












Microservices are in the spotlight as infrastructure building blocks because they offer benefits such as the decoupling of services, data store autonomy, miniaturized development and testing set up, as well as other advantages that facilitate faster time-to-market for new applications or updates. One of the core principles of microservices architecture is the rejection of a monolithic application framework, which in turn favors the sharing of data between services rather than the use of a single large database. Microservices embrace independent, autonomous, specialized service components, each with the freedom to use its own data store.
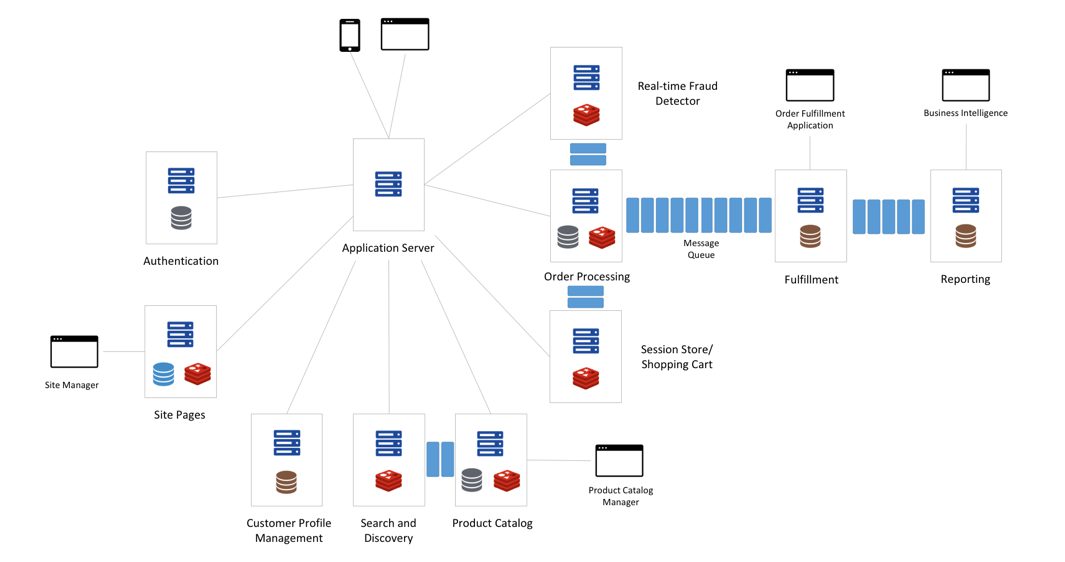
Figure 1. Microservices in a sample e-commerce solution
How to Choose the Right Data Stores for Your Microservices
One of the most important questions to answer while designing microservices is, “How does one choose the right data store(s) for each microservice?” You should incorporate performance, reliability and data modeling requirements into your selection process.
Performance requirements

With microservices, it’s important to design every service to provide the best throughput. If one microservice becomes a bottleneck in the flow of data, then the whole system may collapse.
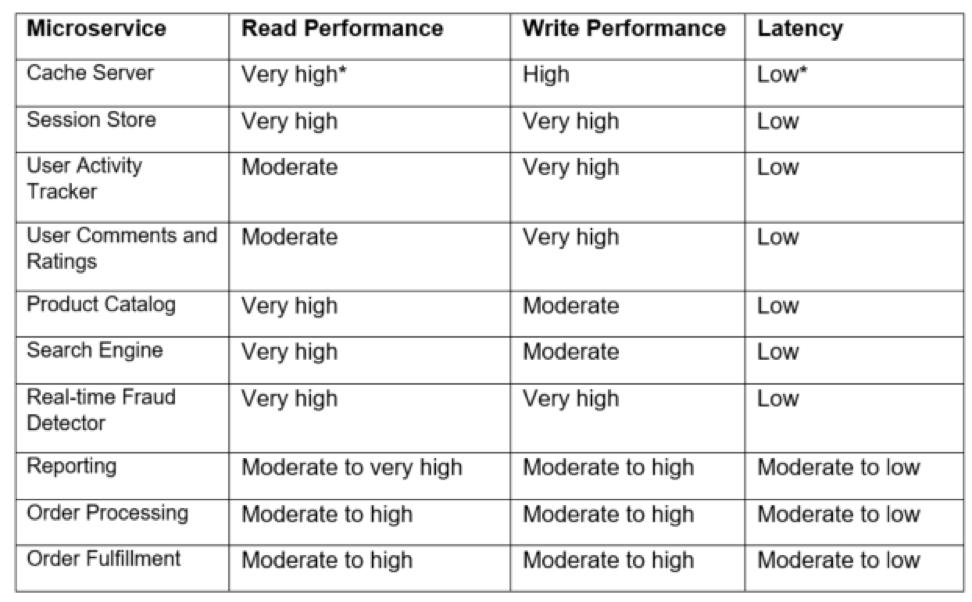
- Read performance: Commonly used metrics for read performance are either the number of operations per second or a combination of how fast you can run queries and how fast you can retrieve results. The speed of retrieving results is dependent upon how well you can organize and index data. An e-commerce product catalog microservice, for example, may run queries that apply multiple parameters such as product category, price, user rating, etc. The database that you choose for such a microservice must first allow you to organize the data to run your queries faster, and then be able to accommodate the number of operations-per-second requirement as well.
- Write performance: The easy metric here is to determine the number of write operations your microservice performs per second. Microservices that collect and process transient data need databases that can perform thousands, if not millions of write operations per second.
- Latency: Microservices that deliver instant user experiences require a low-latency database and deploying a microservice close to its database will minimize the network latency.
- Resource efficiency: Reflecting the design principles of microservices and their agility, the database footprint must be minimal while retaining the ability to scale on demand.
- Provisioning efficiency: Microservice components need to be available for rapid development, testing and production, requiring any database service to support the on-demand creation of hundreds of instances per second.
*For read and write operations, these are the typical numbers for operations per second:
- Very high — Greater than one million
- High — Between 500,000 and one million
- Moderate — Between 10,000 and 500,000
- Low — Less than 10,000
*For latency, the typical numbers are:
- Low — Less than one millisecond
- Moderate — one to 10 milliseconds
- High — Greater than 10 milliseconds
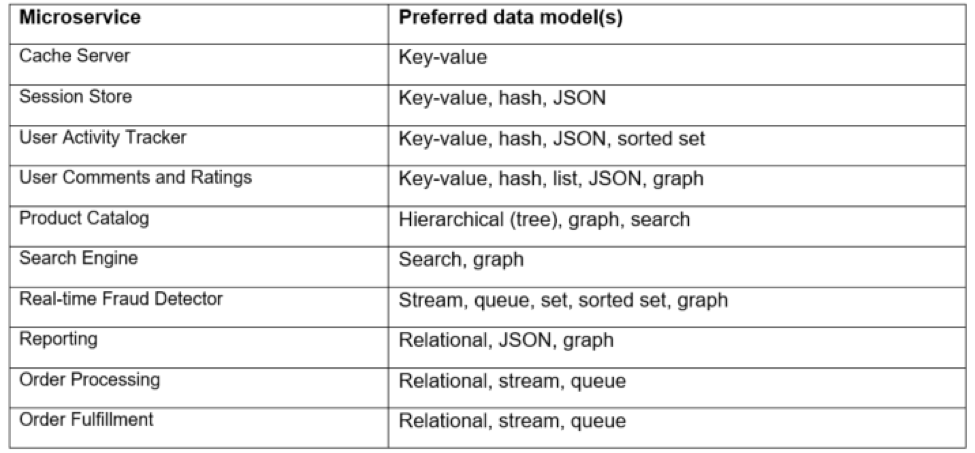
Data Modelling Requirements
The advantage of microservices over monolithic architectures is that each service can choose a database that suits its own data model. A microservices architecture may employ a data model based on key-value, graph, hierarchical, JSON, streams and search engines, among other things. In our example e-commerce solution, data modeling needs could look like the below table:
Nature of Data
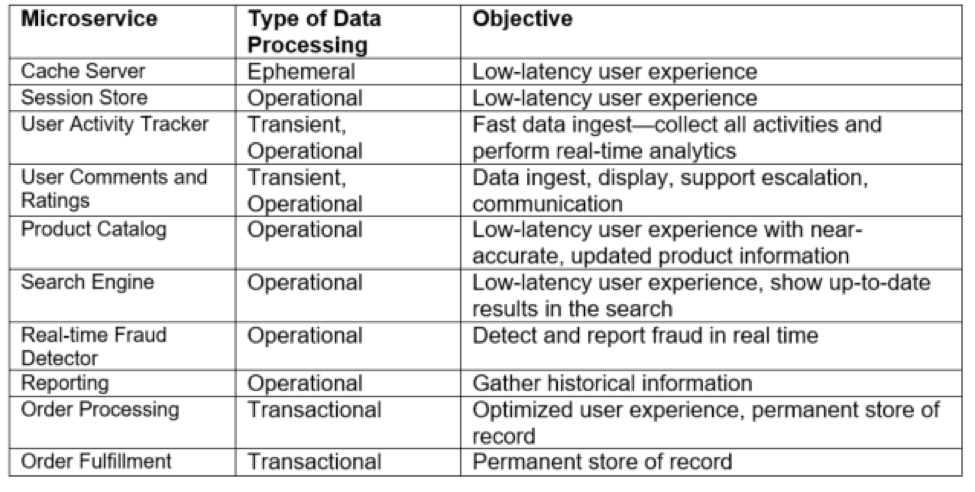
Not all microservices process or manage data at the same stage in its lifecycle. For some microservices, the database could be the source of truth, but for others, it may just be a temporary store. To understand the data needs of your microservices better, you can broadly classify the data in the following categories based on how it is processed:
- Transient data: Data ingest microservices typically process information like events, logs, messages and signals before passing it to the appropriate destination. Such microservices require data stores that can hold the data temporarily while supporting high-speed writes. Since transient data is not stored anywhere else, high availability of the data store used by your microservice is critical — this data cannot be lost.
- Ephemeral data: Microservices that deliver instant user experiences often rely on a high-speed cache to store the most accessed data. One example is a cache server — a temporary data store whose sole purpose is to improve the user experience by serving information in real time.
While a data store for ephemeral data does not store the master copy of the data, it must be architected to be highly available, as failures could cause user experience issues and lost revenue.
- Operational data: Information gathered from user sessions — such as user activity, shopping cart contents, clicks, likes, etc. — are considered operational data. These types of data power instant, real-time analytics and are typically used by microservices that interface directly with users. For this type of data, durability, consistency and availability requirements are high.
- Transactional data: Data such as payment processing and order processing must be stored as a permanent record in a database. The data stores used must employ a cost-effective means of storage, even as volumes of transactions grow.
In the e-commerce solution example shown in Figure 1, you can classify the microservices and their respective data processing needs as shown in the table below:
The other important requirement for your data is to find out whether two or more microservices need to share a common data set. This may happen to all types of data — ephemeral, transient, operational or transactional. In such scenarios, if you design your microservices to access a common database, you risk reverting back to the monolith architecture, and lose the flexibility and local data access advantages of microservices. In a microservices architecture, you can achieve the sharing of data between databases by utilizing messaging systems, or by employing a multi-master, active-active distributed database with “shared nothing” architecture. The latter will provide a local data copy to your microservices and converge all the updates behind the scenes.
Challenges in Selecting the Database to Meet Your Requirements
With over 300 databases available in the market, selecting the right database for your microservice may sound like a daunting task. You may find databases from the list that offer all the features and functions you need. However, the challenge is to find a database that not only meets your criteria but is also lightweight. For efficient orchestration and management, microservices are typically containerized with a light memory footprint.
Operational considerations often drive architects to settle for the lowest common denominator for all use cases — usually a relational database. The slow performance of a relational database doesn’t suit the microservices that rely on accessing the data with sub-millisecond latency and doesn’t allow for flexibility with data models. However, performance with respect to number or read/write operations per second is comparable with that of a relational database.
Top Criteria for Your Microservices Database
Among the most important criteria for your database will be a flexible deployment model, that can be implemented:
- In your own data center, be it on-premises (VMs or bare metal) or in the cloud
- In a containerized environment, orchestrated by Kubernetes or other container orchestrators
- In a cloud-native/PaaS environment like PCF or OpenShift
Ideally, you’ll have a multi-tenant solution that isolates the data between microservices and allows you to tune your database to maintain a trade-off between performance and data consistency/durability. Below are several criteria:
High Performance with Low Latency
The database you choose for your microservices should outpace the other popular NoSQL databases in the market both in higher throughput (number of operations per second) and lower latency. Ideally, its database architecture should be able to perform at least a million read/write operations per second with just two commodity cloud instances, while making sure the data is also durable.
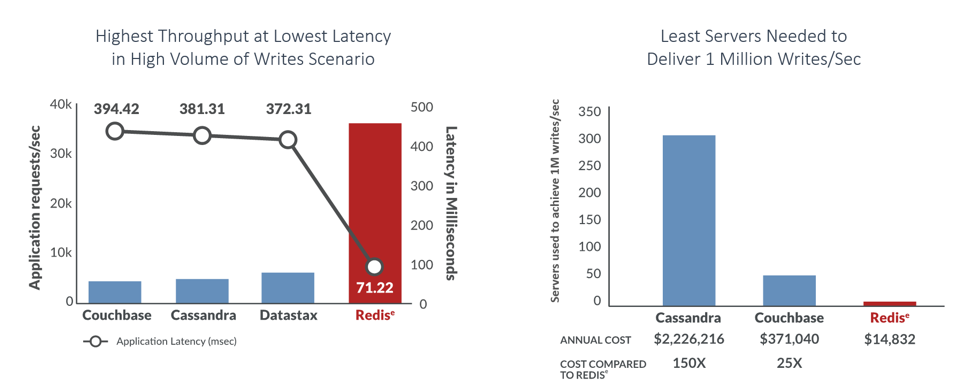
Figure 2. Redis Enterprise performance charts
Redis as a Multimodel Database
For efficiency and scalability, it’s best to have a multimodel database that comes with a host of built-in modules. It should be built over open source, and support all its data structures — Strings, Hashes, Lists, Sets, Sorted Sets, Geospatial Indexes, Hyperloglogs, Bitfields, Streams, etc. — so microservices designers can organize their data using the data structure that best suits their performance requirements.
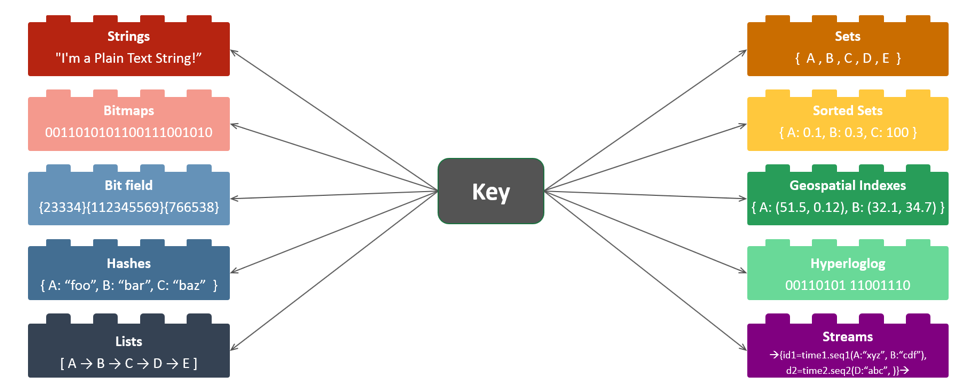
Figure 3. Built-in data structures in Redis
Redis simplifies your application and data architecture. It also simplifies your polyglot architecture (shown below) into a simple streamlined one demonstrated in Figure 4a.
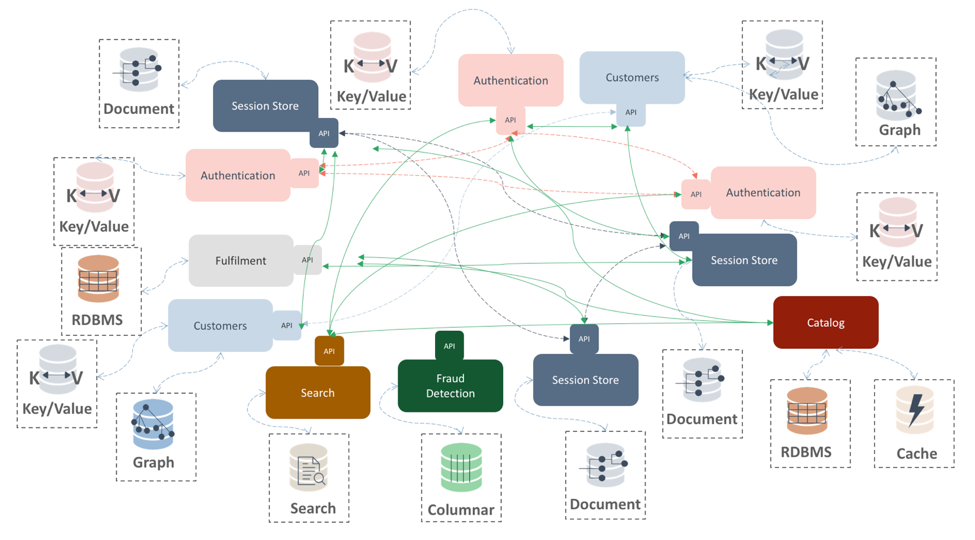
Figure 4a. Microservices — Spaghetti architecture
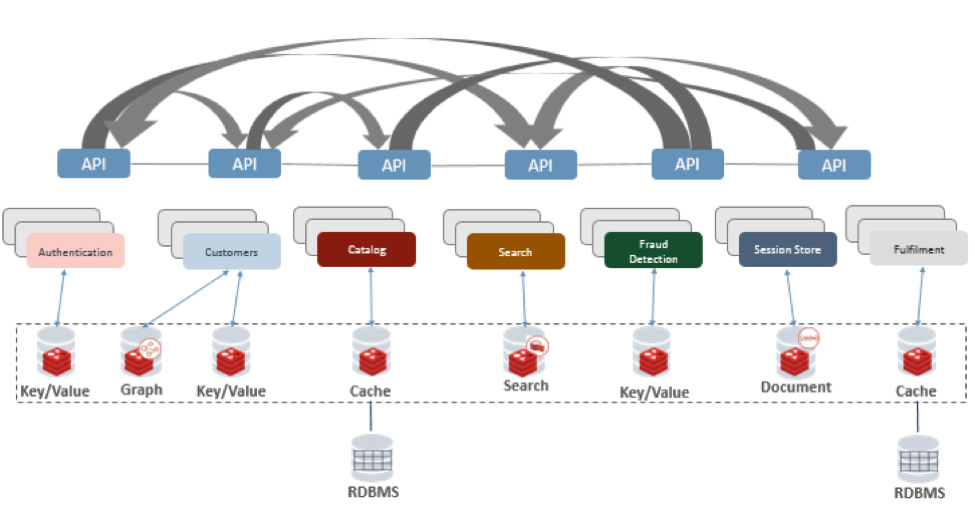
Figure 4b. Multimodel database architecture
High Availability with Automatic Failure Detection
It’s important for your microservices to have a highly-reliable database with always-on availability. The architecture should also offer automated failure detection and zero-downtime scaling completely transparent to the microservices that use it.
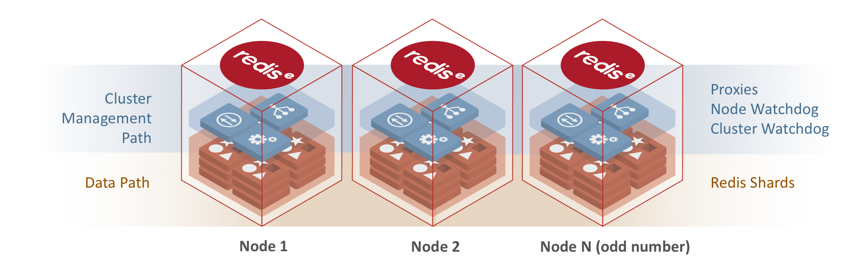
Figure 5. Redis Enterprise architecture for high availability
As shown in Figure 5, the architecture consists of a cluster of container-like Redis Enterprise nodes where each node has an enterprise management layer built on top of open source Redis shards. The management layer has a cluster manager, cluster repository, watchdog entities and UI/CLI/API interface to manage resource provisioning, failovers and several other cluster operations. The data layer includes zero-latency proxies running on every node of the cluster, and diskless replication between the cluster nodes. Should there be a node failure, the nodes establish a quorum by electing the secondary database as the new primary. The architecture supports failover across racks, zones and geographies.
Numerous Durability Options
You’ll want to consider durability options that range from hourly snapshots to log changes every second or every write. The database should be configured to have a combination of in-memory replication and persistence that help you optimize the performance of your microservices for the type of data they handle — ephemeral, transient, operational or transactional.

Figure 6. Strong durability configuration with replication and persistence (AOF every write) on secondary with “wait”
Synchronized Data Across Microservices
Despite all its challenges, a monolithic architecture does guarantee one thing: data consistency. In the microservices approach, you can either use a message stream or a message bus to share messages between microservices. However, if you want to share the dataset across different microservices you’ll need a conflict-free solution to ensure the datasets stay in sync and consistent.
- Shared datasets between microservices — When you have multiple instances of a microservice, each with its own database, an active-active distributed database based on CRDTs is especially handy. Each microservice can perform reads/writes with local latencies, and the databases perform the heavy lifting of resolving conflicts.

Figure 6. Strong durability configuration with replication and persistence (AOF every write) on secondary with “wait”
CRDT-based, distributed databases deliver strong eventual consistency with causal consistency while maintaining local response times (even in geo-distributed scenarios). The database is available for updates even during network partitions, when the network latency between the data centers is very high, and even in the absence of quorum between the active-active servers.
With CRDTs, each microservice can connect to the local instance of a distributed database. The underlying CRDT technology will automatically ensure that all replicas of the data eventually converge to the same consistent state across all microservices.
- Data transfer between microservices — Ideally, there should be three easy ways to transfer data from one microservice to another:
- Pub/Sub: This technique employs the publish-subscribe model for asynchronous communication between microservices.
- Lists: The List data structure supports a blocking call for asynchronous data transfer.
- Sorted Sets: This data structure is good for time-series data but does not enable asynchronous data transfer.
- Streams: Streams data structure combines the benefits of Pub/Sub, Lists and Sorted Sets. It allows asynchronous data transfer, supports connectors for multiple clients, and stays resilient to connection loss.
Operationalizing your microservices
Lastly, it is also important to evaluate your solution’s deployment and orchestration options to ensure that all microservices are deployed and managed in a homogeneous environment. Some key criteria to look for include:
- Multitenant support: A multitenant solution in which the endpoint is a database instance that’s created inside the cluster. The multitenancy also provides very efficient creation of databases to the tune of hundreds of instances per second.
- Availability as a container: Microservices deployed as containers and managed by orchestration tools offer a great deal of operational efficiency but deploying a database as a container can be tricky. However, using a database as a container is a popular choice if it is already part of the application stack.
- Layered orchestration: Popular orchestration systems such as Kubernetes and BOSH are built to manage large numbers of application components, but do not suffice if your applications require a stateful, persistent, highly available database layer. Your database should integrate with such orchestrators and offer its own internal orchestration tools to assure the high availability needed for a stateful, persistent, Redis database layer.
- Kubernetes support: You can also orchestrate a container as a cloud-native database service in your Kubernetes environment.
- Cloud/on-premises options: Whether your microservices run in a private cloud environment, on-premises, or in the cloud, flexible deployment options enable you to keep your microservice as close to the data as possible.
Conclusion
A microservices architecture offers the flexibility and agility that a monolithic architecture cannot deliver. On the flipside, the idea of having a specialized database for each microservice may lead way to a polyglot system, bound to become expensive and difficult to operate over a period of time. Ultimately, you need a high-speed, multimodel database with high availability and durability options that are crucial for your microservices, enabling you to get rid of your monolith architecture while avoiding a polyglot system.
Feature image via Pixabay.















