













Memcached is a popular in-memory key-value store deployed in front of databases to accelerate common queries by caching results. Being an in-memory accelerator, the performance and RAM usage of a Memcached server is critical when running at scale. Performance, measured in transactions per second (TPS), directly affects the number of concurrent client requests that the Memcached server can handle. RAM usage, on the other hand, is measured as memory overhead per object (i.e., metadata overhead) and limits the number of objects that can be cached by the Memcached server. Optimizing Memcached for the aforementioned metrics has been an area of active research both in academia and the industry.
Improving TPS requires scaling Memcached server instances which incur additional costs of cloud instances and associated management overhead. Improving memory overhead requires provisioning high memory instances which typically have a higher cost/hour ratio. The memory overhead is especially critical for small objects (~32 byte keys) that dominate Memcached queries, as reported by Facebook. An alternate approach is to build what we call “dense Memcached” that takes advantage of high core count and nonvolatile memory (NVM).
Dense Memcached
The emergence of NVM presents an opportunity to rethink the Memcached architecture to improve the software performance. In our view, a “dense Memcached” instance is one that can:
- Scale with high core count instances. The current approach with Memcached is to spawn multiple server instances beyond 8 threads, for example, to achieve performance scaling.
- Use both memory and NVMs for caching. This enables access to 100s of GBs to TBs of storage at sub-millisecond access latency whilst providing high TPS.
Note that, (i) both throughput bottlenecks and metadata footprint are due to software limitations and therefore, can be improved upon; and (ii) the availability of high core count instances and NVMs with latencies in the 10s of usec can be leveraged to build dense Memcached instances.
Design of Dense Memcached
We leveraged Helium, our key-value store, to build an implementation of dense Memcached. Helium is a high throughput, low latency, and low memory key-value store written from the ground up for modern multi-core processors and NVMs. The core Helium library is an embedded key-value store and thus falls in the same category as RocksDB.
We started with a simple design where Memcached set commands were stored in memory and written as a key-value pair to Helium. On the get/read path, a key is first checked in the cache and then the Helium data store. In this naive approach, despite the added benefit of increased capacity, it quickly became evident that Memcached was the bottleneck when scaling to 32 threads or higher. The scaling and synchronization problems experienced with Memcached are inherent in the cache algorithm of Memcached. Also, this approach wasn’t much different than having Memcached as a frontend cache for a backend persistent database.
Recent trends in hardware presents an opportunity to rethink the Memcached architecture to not only improve the software performance but also fully leverage the advantages of NVMs.
In our second approach, we used Helium as the key-value store with a front end that is essentially Memcached network processing and protocol parsing. This approach leverages the strengths of both key-value stores and Memcached, i.e., the low latency network processing path and the command/protocol processing maturity of Memcached coupled with the scaling, low memory indexing, and fast IO path of Helium.
The figure below shows the overall design of dense Memcached using Helium. Note that the use of NVMs such as 3D Xpoint (aka Intel Optane) from Intel and z-SSD from Samsung enables latencies in the order of tens of microseconds from the hardware. The software overhead of Helium is also in a similar range (i.e, few microseconds) to make this an efficient solution.
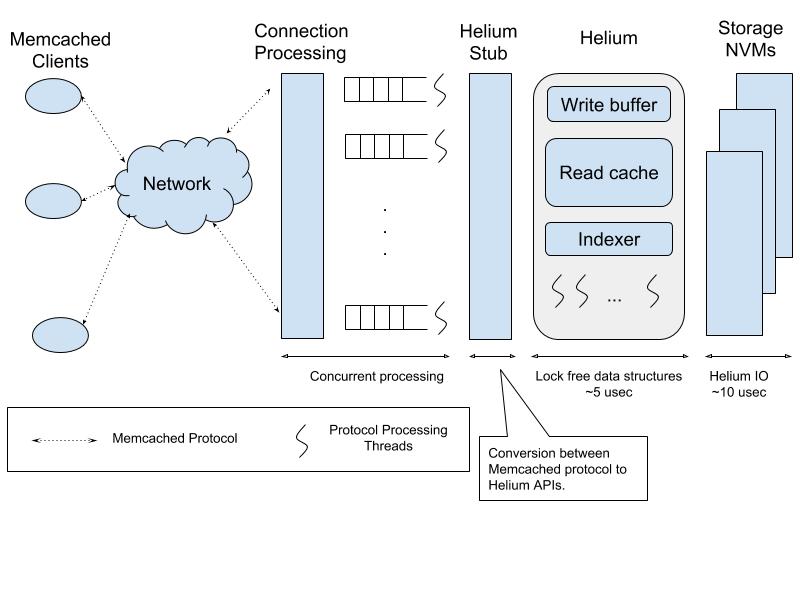
Figure: Helium Memcached Architecture
Advantages
We call this version of dense Memcached “He-Memcached,” the advantages of which are below.
Single Instance Scaling
A single instance of He-Memcached scales with increasing core/thread count. Memcached, on the other hand, scales poorly beyond eight to 16 threads due to inherent locking and synchronization. For example, at 90:10 (get:set) ratios, Memcached has scaling issues due to locking/contention in its core data structures on the write (set) path. Single Memcached server instance scaling is important because it enables provisioning of any cloud instance type. This reduces management complexity, such as partitioning, and thus uses the server memory more efficiently by aggregating multiple Memcached instances into a single, unified memory space.
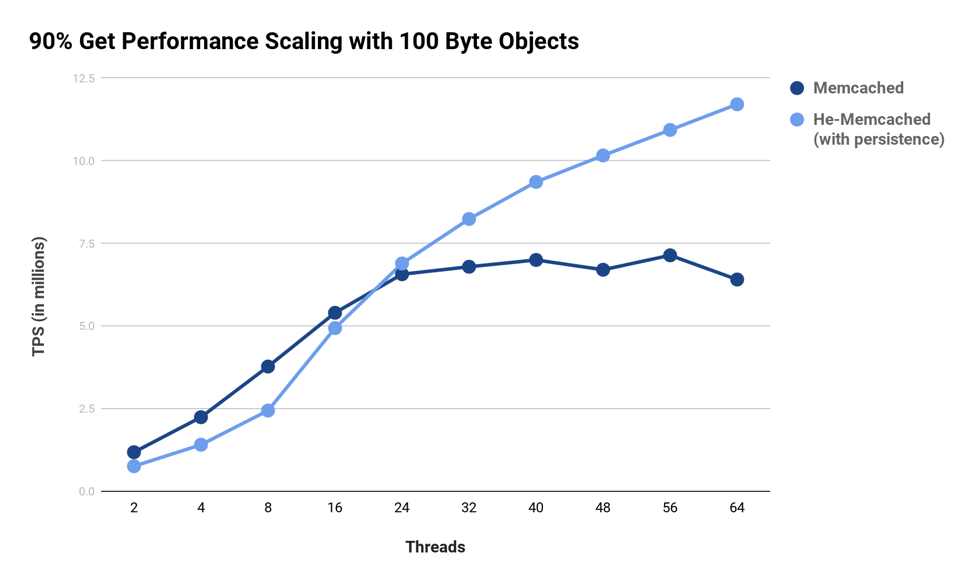
Setup: server Intel Xeon 88 CPUs; storage Intel Optane 750 GB; memtier benchmark over 10GbE network.
As demonstrated in the chart above, Memcached’s scaling performance is tolerable for workloads dominated by gets. However, for workloads that have a greater percentage of sets, the locking contention in Memcached’s write path becomes increasingly evident. For a common 70:30 (get:set) ratio workload, the results of Memcached thread scaling are demonstrated in the following chart. We can see that a “dense Memcached” implementation overcomes the scaling issues present in Memcached for both workloads while providing persistence (In this case using an Intel 3D Xpoint NVMe storage).
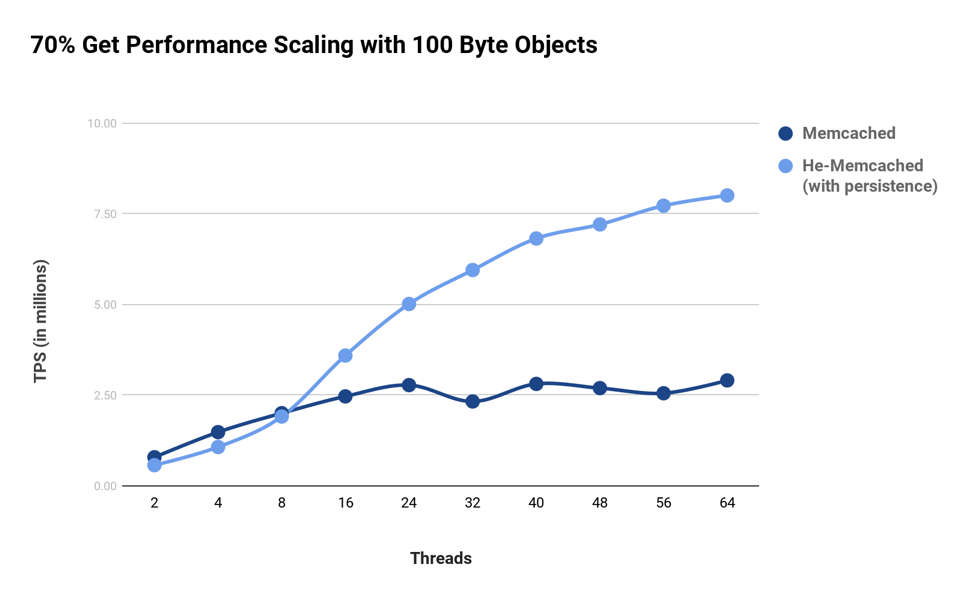
Setup: server Intel Xeon 88 CPUs; storage Intel Optane 750 GB; memtier benchmark over 10GbE network.
Persistence
Helium as a key-value store treats storage as a first-class citizen. Integrating Helium as a storage engine inside Memcached brings persistence along with the associated performance benefits. For example, the core of Helium is written to access the indexer (i.e., a key) and its associated data (i.e., value) using lock-free data structures and an I/O path that is optimized for NVMs. The data access (software) overhead matters when the NVM latencies are in the 10 usec range. The use of lockless indexing and optimized NVM access results in software latency that is a few microseconds to match with the 10 usec NVM latency.
While this access latency to objects on NVM is still higher than the memory access (which is in nanoseconds), it is important to note that — (i) this is better than a memory cache miss followed by access to the database over the network that is typically in the order of several milliseconds, and (ii) the overall TPS is a mix of caching (memory hits) and NVM (memory miss). Essentially, the goal is to make the actual database a “level-2” miss, the first and second level miss being memory and NVM.
Reduced Indexing Overhead
The metadata overhead of Memcached is 56 bytes per object. With Helium, we reduced this to 22 bytes. The difference of 34 bytes in overhead potentially translates to several gigabytes of memory/storage reduction when caching 100s of millions of objects.
Summary
With high core count instances and the availability of NVMs such as Intel 3D XPoint and Samsung Z-SSDs, it is economical to develop dense Memcached solutions. Going forward with a dense Memcached implementation, we envision that the performance bottleneck now moves to a 10 GbE network.
In summary, the majority gains are from the following:
- Lockless indexing in Helium that performs well for mixed set-get workloads.
- Removing LRU lists that have both synchronization and metadata overhead.
- Removing the GC and hash load balancer threads. This is taken care of by Helium’s built-in GC.
- Simplify the slab allocator by making it lock-free.
- Relying on Helium for indexing and IO path.
- Using Helium as an engine that is:
- Written in C and therefore does not have an overhead of language memory management stalls.
- Performs direct IO to the NVMs bypassing the file system for optimal latency.
- Relies on modern parallel processing best practices such as lock-free data structures, spinlocks, etc.
Feature image via Pixabay.















