












- Home
- >
- DevOps News
- >
- Take Control of Your Observability Data Before It Controls You – InApps Technology 2022
Take Control of Your Observability Data Before It Controls You – InApps Technology is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn Take Control of Your Observability Data Before It Controls You – InApps Technology in today’s post !
Read more about Take Control of Your Observability Data Before It Controls You – InApps Technology at Wikipedia
You can find content about Take Control of Your Observability Data Before It Controls You – InApps Technology from the Wikipedia website

Ed Bailey
Ed is a passionate engineering advocate with more than 20 years of experience in instrumenting a wide variety of applications, operating systems and hardware for operations and security observability.
Enterprises are facing an unprecedented wave of operational and security observability data. The data is complex, multidimensional and high velocity. Enterprises are consistently underestimating the scale and scope of data they need to support their operational and security observability platforms.
Steve Waterworth, while at Instana, ran an interesting experiment by creating a static workload for a very simple Kubernetes-based microservice application. He predicted total observability data would be less than 100 gigabytes of data over a 24-hour period, but it actually was over 400GB of data. And if you think about it, adding security data on top of operational datasets expands the total even more. Even small applications can generate a wave of data with high velocity and complexity.
So how can enterprises avoid drowning in data?
To paraphrase Nick Fury, enterprises can start by keeping both eyes open to understand the drivers of data growth and recognizing that the challenges they’ve been facing can be overcome.
Understand the Drivers of Data Growth
- Modern systems are generating enormous volumes of log data.
- Stringent security compliance and government regulations require enterprises to retain even more data for longer.
Recognizing the Challenges
- Lack of standardized log formats.
- Tooling to efficiently and cost-efficiently manage huge volumes of data.
- Inability to consistently get insight into so much data.
Enterprises have to control their data plane, the interstitial layer between your data sources and your observability tooling, if they have any hope of managing costs and increasing the effectiveness of their observability strategy. The essence of observability is deriving deep insights into your data, which is nearly impossible if you have so much data that you cannot understand and process it efficiently.
The cost of an unmanaged data plane is substantial. Unmanaged observability data generates enormous costs for software licensing and storage, and it is a drain on engineering time that leads to opportunity costs.
There are three types of enterprises:
- Enterprises that log everything and pay enormous bills to observability and storage vendors.
- Enterprises that will choose to not log everything they need and will accept the operational and security risks for gaps in data.
- Enterprises that actively manage their data plane and are able to log the right data as efficiently as possible to their observability tools, in order to get the best quality and quantity of data.
The first type of enterprises are a boon to vendors, but may not be doing themselves a favor since data quality has to be managed. These enterprises are effectively just logging a lot of potentially bad data, with no guarantee for better insight into said data.
The second type of enterprises are taking on enormous operations and security risks by choosing not to consume data into their operational and security observability platform. Given the way security issues are escalating, how much longer can accepting a weaker security posture be acceptable?
The third type of enterprise has the ability to control its data plane. It can manage all of its data and direct the right data to the right tool in the right format. It can remove useless data from the event stream and not sacrifice data quality. This enterprise does not have to accept the risk of not logging relevant data, and in fact, it can bring more use cases to its observability platform due to its ability to control its data plane.
What Is a Data Plane and What Are Options for Controlling It?
I briefly explained what a data plane is earlier: It’s the interstitial layer between your data sources and your observability tooling. But this illustration does a much better job:
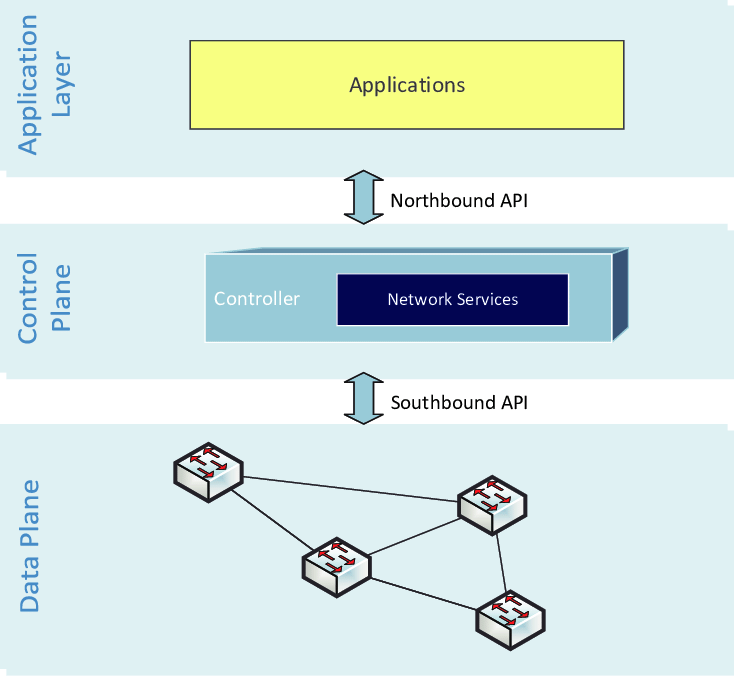
More specifically, a data plane is the layer where raw data lives in its many forms. The velocity and complexity of data in this layer is daunting. Most observability vendors license their tools on data ingested or workload generated by this data. They have no motivation to help you manage the data plane, since it limits how much money they can make. Enterprises have to look outside their traditional platform vendors to get the right mix of capabilities, by either buying or building solutions.
Here’s what the data plane looks like for most enterprises (yours too, probably):
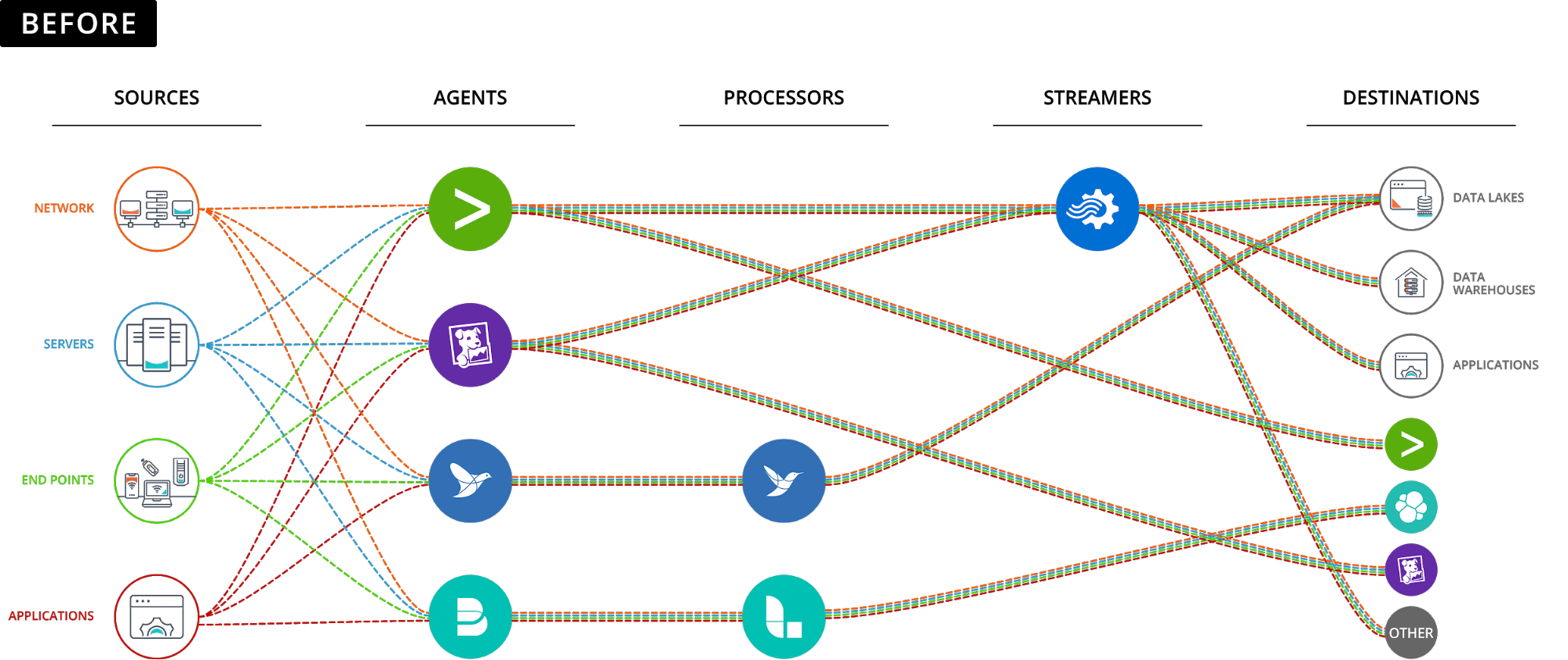
Enter the Observability Pipeline
An observability pipeline is a universal receiver and sender of data: It collects any and all data (e.g. metrics, events, logs, and traces), and then shapes and routes that data to where it’s needed most (e.g. from Elastic to Splunk to Exabeam) without re-training users or replacing any existing tooling.
An observability pipeline brings broad options for consuming data from numerous sources and transforming that data in real time into more efficient formats, which could include dropping fields, adding fields or condensing from one form (e.g. logs) into another form (e.g. events). Ultimately, observability pipelines put the enterprise in control of the data plane to get the best, most efficient results for its observability needs:

Build or Buy?
Once enterprises decide to invest in the observability pipeline, the next challenge to tackle is “build or buy?”
A good guiding question is, “Where do you want to invest your precious engineering time?” In highly standardized application stacks with limited formats, it can make sense to invest in a solution based on open source tools like Logstash and Kafka to manage your data, since complexity and the rate of change are lower.
However, be very careful to make sure that you allocate enough time to build integrations between your tools, your observability pipeline and your observability stack. For every custom integration, you will need to allocate time for updates, as tools evolve and security issues are discovered. This is a spiral that will eat up more and more engineering time. It certainly can be done successfully, but be aware of engineering time allocation and how it will grow over time.
The Bottom Line
Enterprises have to make the choice to either accept the current situation and drown in data, or adopt an observability pipeline to take control of your data to get the best, most efficient result from your operational and security observability solutions. Better data that costs less to manage will drive better operational and security outcomes across the enterprise.
One observability pipeline you can try out is Cribl’s free, hosted LogStream Sandbox (you don’t need to install anything and you’ll get a certificate of completion for each course). I’d love to hear your feedback; after you run through the sandbox, connect with me on LinkedIn, or join our community Slack and let’s talk about your experience!
List of Keywords users find our article on Google:
| incontrol apps |
| essence drain build |
| instana reviews |
| cribl |
| elastic observability |
| let’s sacrifice toby |
| exabeam jobs |
| rundeck enterprise vs open source |
| splunk apps |
| rundeck community |
| hire logstash developers |
| pagerduty vs splunk |
| splunk connect for kubernetes |
| rundeck integration |
| hire meteor consultant |
| pagerduty observability |
| splunk kafka |
| cribl jobs |
| the sandbox linkedin |
| exabeam vs splunk |
| splunk time format |
| splunk vs pagerduty |
| cribl vs splunk |
| allocate software linkedin |
| cost control wikipedia |
| it controls |
| splunk remove data |
| design ready controls jobs |
| instana jobs |
| kafka to splunk connect |
| pegas spiral |
| exabeam headquarters |
| splunk kafka connect |
| instana observability |
| kafka connect splunk |
| lets sacrifice toby |
| time format in splunk |
| splunk case |
| splunk connect for kafka |
| elastic splunk |
| what is cribl |
| slack sandbox |
| logstash fields |
| splunk mission control |
| kafka vs logstash |
| rundeck |
| splunk stream |
| kafka observability |
| kafka to splunk |
| splunk training cost |
| logstash pagerduty |
| logstash kafka |
| work allocation software |
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.














