












- Home
- >
- DevOps News
- >
- Operationalizing Chaos Engineering with GitOps – InApps 2022
Operationalizing Chaos Engineering with GitOps – InApps is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn Operationalizing Chaos Engineering with GitOps – InApps in today’s post !
Read more about Operationalizing Chaos Engineering with GitOps – InApps at Wikipedia
You can find content about Operationalizing Chaos Engineering with GitOps – InApps from the Wikipedia website
Kubernetes is the core substrate around which the cloud native ecosystem operates. The convergence properties of Kubernetes lend to the purest implementation of GitOps. While the initial adoption of GitOps tooling centered around “Kubernetes deployments as code” that are synched with target clusters, it has evolved to manage drifts in core platform infrastructure with the emergence of projects such as Cluster API and Crossplane.
GitOps as a Core Principle of CNCE

Karthik Satchitanand
Karthik is a co-founder and the CTO of ChaosNative.
When the LitmusChaos authors defined cloud native chaos, the idea was definitely to keep the chaos/resilience testing methodology and experience homogeneous with other Kubernetes functions via the usage of custom resources (CRDs) to define fault injection and steady-state validation intent. This type of definition lends itself to storage in a git source, and hence audit, versioning and automation.
Automation is a core principle in chaos engineering. While this holds true for any engineering system, its relevance in the cloud native environment is more. This is driven by a relatively faster upgrade cadence of core application services, dependent tooling from the CNCF (Cloud Native Computing Foundation) ecosystem, Kubernetes versions and sometimes the underlying hosting infrastructure itself. By executing chaos tests, changes can be verified. This calls for chaos experiments to be tied with standard GitOps flows.
Requirements and Challenges
As the above discussion reveals, the following are requirements of effective chaos engineering with GitOps:
- Single source of truth: Ensure chaos artifacts are stored in a single source of truth and ensure that the latest experiment definitions are always picked.
- Automated testing: Ensure that core application changes, facilitated by GitOps controllers, are tested by automated chaos injection.
While the immediacy of the need is clear, there are some practical challenges:
- On-demand and scheduled runs: Chaos experiments are typically executed as on-demand or scheduled tasks. This is especially true about experiments that are end-to-end and involve steady-state checks, synthetic loads and other instance/run-oriented actions. These are often executed via some kind of control plane that itself qualifies as a Kubernetes app. As such, they are unlike standard application resources that “live” all the time. This is despite their declarative definition.
- At-source definition changes: While the previous challenge is overcome by intelligent design of tooling, it may not be desirable to inject chaos whenever a test’s definition changes at source. The trigger for chaos injection should be controlled by the owners/stakeholders of the deployment environment and should be willful.
- Mapping chaos tests: There is a need to map applications and infra-components with a specific suite of chaos tests. While chaos by definition is random and experimentation by nature exploratory, there is value in the categorization of experiments, as well as validation of the known and capture of unknown behaviors in case of automated runs.
GitOps Implementation in LitmusChaos
Litmus addresses these requirements through a custom GitOps implementation that ensures the control plane residing on the cluster picks the latest chaos definitions in the git source, maps applications to specific scenarios or workflows and launches these upon changes to the apps on the cluster.
The Litmus control plane, which runs as a set of Kubernetes microservices, carries out interactions with git in a couple of different ways.
Static Chaos Artifacts on ChaosHub
Litmus provides readily usable fault templates while also allowing users to construct more complex workflows using these faults, called predefined workflows in litmus lingua franca. These can be stored in a specific structure in a git repository that serves as the canonical source of a “ChaosHub.”
Each chaos experiment or predefined workflow is characterized by a set of files: the core custom resource, (optional) RBAC definitions to carry out the experiment and some metadata files (containing descriptions, keywords, source links, parent category, etc.). Such a ChaosHub, public or private, connected via SSH keys or access tokens, can be added into the Chaos-Center and leveraged as a catalog to choose experiments executed on the cluster. Changes made at source, via user commits, to the fault or workflow templates are made available to developers for subsequent invocation of the experiments.

Bi-directionally Synched Chaos Workflow Definitions
While the previous section describes hand-written chaos artifacts, there are mechanisms to ensure chaos workflows constructed using the chaos dashboard on the cluster are saved into source, facilitating a golden copy. The Litmus server runs a git service by which newly constructed workflows are stored into a git repository, which can be the same as the one serving as the hub source or a different one, along with instance metadata of the workflow, its associated control plane and the target cluster environment. This git service is bidirectional in nature; for instance, changes made into these workflow specs on the git repository are automatically synchronized into Chaos-Center. The updated specs can be leveraged for subsequent invocations of this workflow.

Event-Triggered Chaos Injection
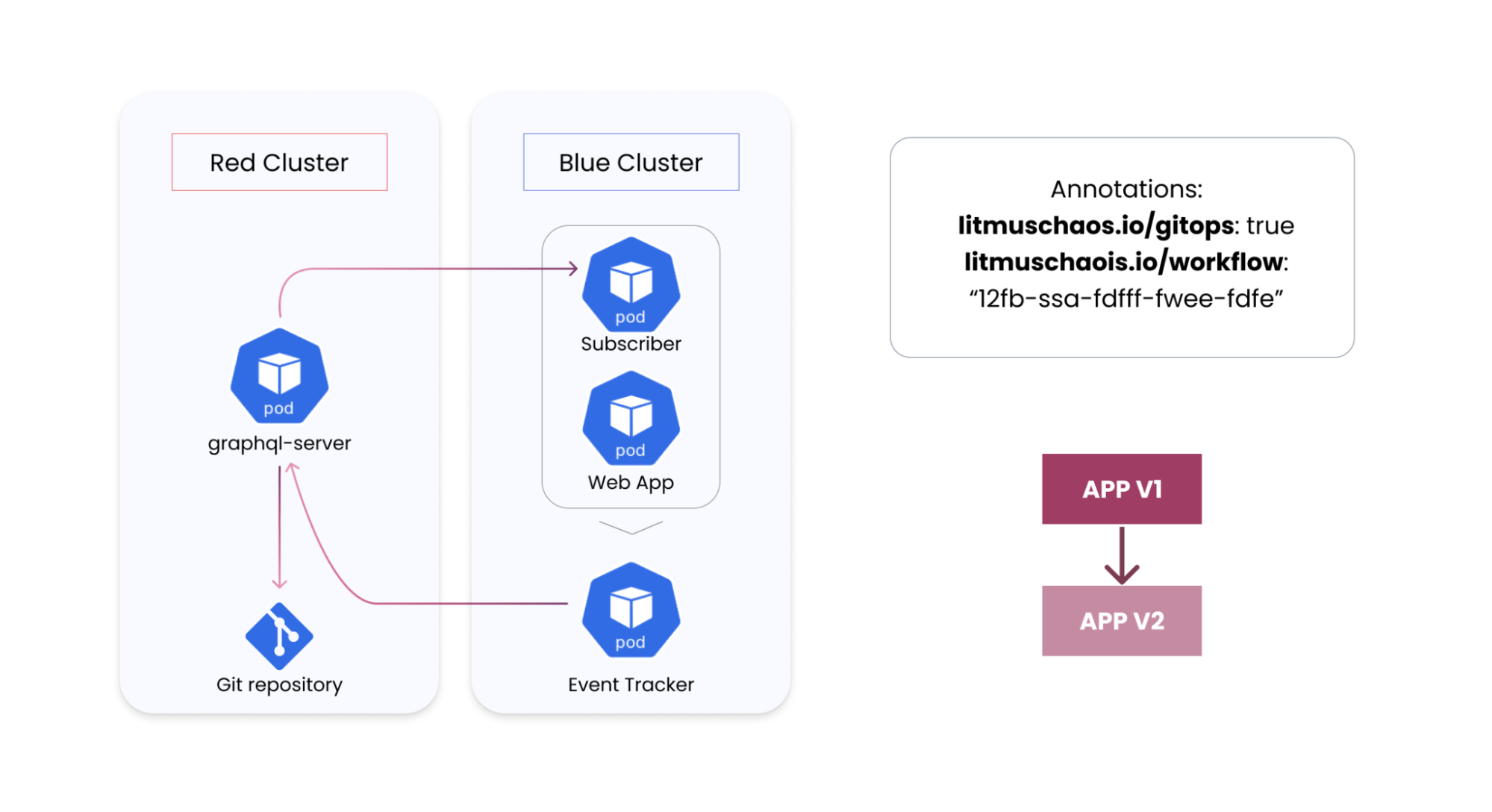
With the chaos-artifact changes being made available, the next requirement is to map these workflows with applications on the cluster. This is accomplished by the event-tracker operator in Litmus, which enables a subscription model wherein a given Kubernetes workload can subscribe to a git-synced chaos workflow on Chaos-Center and also describe the event that triggers this workflow, declaratively via an EventTracker policy resource.
The event tracker watches for the said change on the application workload, which lends itself to monitoring via annotations, and triggers the workflow once the change is made, having mostly occurred through sync-actions of standard GitOps controllers. This way, the sanity chaos tests can be performed, with rollback mechanisms set up by users based on the ChaosResults reported by the experiments.
LitmusChaos is simple to deploy on your Kubernetes cluster or namespace. Sign up at litmuschaos.cloud for a quick start on chaos engineering or follow the docs to install Litmus on your own Kubernetes cluster.
Featured image provided by ChaosNative.
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.














