












- Home
- >
- DevOps News
- >
- Continuous Integration and Continuous Delivery (CI/CD)
Continuous integration and continuous delivery (CI/CD) is one of the driving forces behind DevOps. If your organization is considering a DevOps approach, CI/CD will be part of it. But what does it really mean and why is it so critical? To strategize about your DevOps toolkit and rollout with IT, understanding the basic concepts of CI/CD is key. In this article, we’ll explore the pain points CI/CD addresses, the tools you’ll need, and the benefits you can expect.
Let’s start with the big picture. DevOps aims to create a workflow from left to right with as little handoffs as possible and fast feedback loops (for an introduction to DevOps, please refer to our previous article). But what does that mean? Work, in our case code, should move forward (left to right) and, if possible, never back to be fixed again. Problems should be identified and fixed when and where they were introduced. For that to happen, developers need fast feedback loops. Feedback is provided through fast automated tests that will validate if the code works as it should before moving it to the next stage.
To decrease handoffs, small groups will work on smaller functionalities (versus an entire feature) and own the entire process: create the request, commit, QA, and deploy — from Dev to Ops or DevOps. The focus is on pushing small pieces of code out quickly. Why? Because the smaller the change going into production, the easier it is to diagnose, fix, and remediate.
This fast flow from left to right is enabled by a continuous integration (CI) and extended to actual production deployment by continuous delivery (CD). We see this often referred to as CI/CD. That’s the 10,000-foot view, now let’s dive deeper.
Key Summary
- Overview: The article explores Continuous Integration (CI) and Continuous Delivery (CD), essential DevOps practices for automating and streamlining software development, as presented by InApps Technology in 2022.
- Key Points:
- Continuous Integration (CI):
- Definition: Developers frequently merge code changes into a shared repository, with automated builds and tests to detect issues early.
- Key Features:
- Automated testing (unit, integration) on every commit.
- Centralized version control (e.g., Git on GitHub/GitLab).
- Fast feedback loops to fix bugs quickly.
- Tools: Jenkins, GitLab CI, CircleCI, Travis CI.
- Continuous Delivery (CD):
- Definition: Extends CI by automating the deployment of tested code to staging or production, ensuring software is always release-ready.
- Key Features:
- Automated deployment pipelines for consistent releases.
- Manual or automated approval gates before production.
- Rollback mechanisms for failed deployments.
- Tools: ArgoCD, Spinnaker, Azure DevOps.
- CI/CD Pipeline Workflow:
- Code commit triggers automated build.
- Tests (unit, integration, end-to-end) validate changes.
- Artifacts are deployed to staging for further testing.
- Approved changes are deployed to production (manual or automatic in Continuous Deployment).
- Supporting Technologies:
- Containerization: Docker for consistent environments.
- Orchestration: Kubernetes for scalable deployments.
- Infrastructure as Code: Terraform, Ansible for automated provisioning.
- Monitoring: Prometheus, Grafana for post-deployment observability.
- Continuous Integration (CI):
- Use Cases:
- Rapid feature releases for SaaS applications.
- Ensuring reliability in microservices architectures.
- Streamlining updates for mobile or web apps.
- Benefits:
- Speed: Accelerates development with automated workflows.
- Quality: Reduces bugs through early, frequent testing.
- Reliability: Ensures consistent, repeatable deployments.
- Collaboration: Enhances team productivity with shared pipelines.
- Challenges:
- Initial setup of CI/CD pipelines requires time and expertise.
- Maintaining complex pipelines for large projects.
- Ensuring security in automated deployments (e.g., secrets management).
- Cultural shift needed for teams new to DevOps practices.
- Conclusion: In 2022, CI/CD, as highlighted by InApps Technology, transforms software delivery by automating integration and deployment, enabling faster, more reliable releases with tools like Jenkins and Kubernetes, though successful adoption demands robust setup and cultural alignment.
Continuous Integration: A Deeper Dive
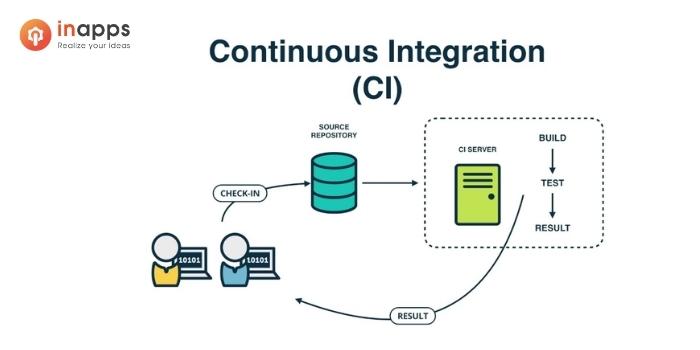
First, we’ll focus on the continuous integration part of CI/CD. This is what you’ll need to master first. In fact, most companies only do CI. For CD, you’ll need to be a mature DevOps enterprise already.
So, continuous integration. With integration, we mean integrating code (an update or new feature) developed by a programmer on their local machine into the codebase (the rest of the app). This leads to three challenges:
- Keeping track of all changes so, should an error occur, you can still revert back to a previous state to avoid or minimize service disruption.
- Managing conflicts when multiple developers are working on the same project at the same time
- Catching errors before adding new code to the codebase
We’ll discuss three tools that address these pain points.
1. Version Control
As code moves from Dev to Ops it’s continuously tweaked based on test results. All these changes must be captured in a version control system. Version control is a software tool that helps developers manage source code changes over time. It keeps track of all changes in a special type of database.
Ideally, all parts of the software system should be captured here. That includes:
- Source code
- Assets
- Environment
- Software development documents
- Any changes to the files stored within the systems
2. Master and Developer Branches
Typically, multiple developers will work on the same project. These can range from a handful to hundreds of programmers — a potentially messy state of affairs. To alleviate the risk of destabilizing or introducing errors into the version control master, each developer works on different parts of a system in parallel. They do this via “branches” on their local machines.
But working on branches isn’t a solution in itself, the code that each developer is working on must still be integrated into the codebase, which is continuously evolving.
The longer developers work in a branch without committing to the master, the more difficult it becomes to integrate and merge with everyone’s changes in the master. The difficulty increases with the number of branches and changes in each branch. So, since the longer developers work on their code without committing, the more difficult it gets, the logical answer is to increase frequency. Better yet, make it continuous. There you go, that’s continuous integration.
The graphic below depicts exemplifies how the different branches are visualized. Blue is the master branch and all other colors are individual developers working on their own branch which is eventually merged into the master branch.

Different branches of the Kublr Docs page: Blue is the master branch and all others are individual development branches. Developers work on their own workstation and merge their changes multiple times a day or by the end of the day.
It’s not all sunshine, though. Even if a developer commits code on a daily basis, conflicts will still occur. Other team members will have worked on and committed their own changes, that other parties weren’t accounting for. Indeed, integration problems often require rework, including manually merging conflicting changes. However, it is exponentially easier to figure out and fix conflicts in a day’s worth of work, than if a development team has been working on it all week or month. So, while integration problems are not avoidable, CI significantly reduces them.
3. Deployment Pipeline and Automated Tests
Catching errors and making sure code is in a deployable state is part of quality assurance (QA). Traditionally, QA was handled by a separate team only after development was completed. Often only performing tests a few times per year, developers learned about mistakes months after the change was introduced.
By then, the link between cause and effect had likely faded, leading to an increasingly difficult diagnosis. Automated testing addresses that very issue.
Using a deployment pipeline, a software tool, a series of tests are triggered each time code is added to version control. The pipeline automatically builds and tests code to ensure it works as intended and continues doing so once integrated into the codebase.
While code can work perfectly within a test environment, it can still fail miserably once it goes into production where the environment and all dependencies will impact code performance. Dependencies are components that aren’t part of the app but are needed to run it.
Examples include databases, data/object storage, and services the application may call over an API. That’s why development and test environments must mimic the production environment. Additionally code must be tested with all dependencies.

Individual steps when code is committed to version control
In short, there are three test stages when deploying code, each adding additional complexity: (1) validating that the code itself works as intended, (2) that it continues doing so within the codebase, and (3) that performance persists in a production-like environment with all dependencies.
If code is committed to version control daily it can be automatically tested, and any build, test, or integration errors will be flagged the day they are introduced, enabling immediate fixes. This ensures code is always in a deployable and shippable state, referred to as a green build.
Automated tests allow developers to increase test and integration frequency from periodic to continuous and find problems while there are the fewest constraints. Worst case scenario, a whole day of work is lost.
Sidenote: Version Control Controversy
There is some discussion on whether sensitive information such as access tokens, keys, and passwords should be stored in version control. On one side of the spectrum, there are people who believe everything, including secrets, should be stored here, pushing the approach to the limit. Then there are those who consider it bad practice and argue that sensitive information should be stored separately.
Both approaches have their pros and cons, apostles and haters, and techniques that make them feasible and secure. All changes in the version control system are called commits or revisions.
Version control allows developers to compare, merge, and restore past revisions. It minimizes risks by allowing them to quickly revert the system in production back to a previous version should a problem occur.
For this to work, all updates and changes, no matter how small, must be tracked in version control. If they aren’t, the code in production won’t match the code in development and test environments, leading to inconsistencies and problems down the line.
In short, version control is a single source of truth that contains the precise intended state of the system as well as all previous states. By putting all production artifacts into version control, developers can repeatedly and reliably reproduce all components of the working software system. This is key to enabling so-called immutable infrastructures, we’ll come back to that later.
Continuous Delivery: Extending CI for Smooth Code Deployment
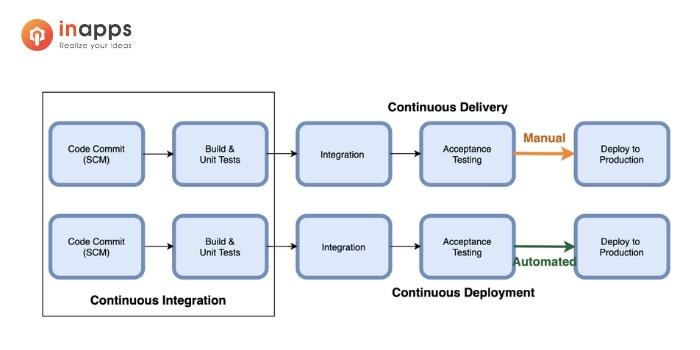
Even when continuously integrated, deploying code into production can still be manual, tedious, and error-prone. If that’s the case, it will clearly happen less often. IT, just like anyone else, will avoid difficult and risky tasks when possible. This leads to ever-larger differences between code to be deployed and code running in production, fueling a risky vicious cycle. The answer to that is continuous delivery — the CD part of CI/CD.
CD extends CI to ensure code runs smoothly in production before rolling it out to the entire user base. The most common CD approaches are canary and blue-green deployments.
During a blue-green deployment, IT deploys a new component or application version alongside the current one. The new version (green) is deployed to production and tested while the current version (blue) is still live. If all goes well, all users are switched to the new version.
Canary deployments are similar in that we have two versions: the current one and the updated version. IT starts routing a small share of user requests to the new version. Code and user behavior are continuously monitored. If the error rate or user complaints do not increase, the share of requests routed to the new version is incrementally increased (e.g. first 1%, 10%, 50%, and 100%). Once all requests are sent to the new version, the old version is retired or deleted.
Self-Service Through On-Demand Environment Creation
Now that we’ve explored CI, CD and their respective tools and approaches, let’s discuss environments and infrastructure. CI/CD calls for a novel approach.
As we’ve seen, automated tests enable developers to perform QA themselves. To ensure everything works in production, they must use production-like environments throughout development and testing.
Traditionally, developers would have to request test environments from the Ops team that were (manually) set up. This process could take weeks, sometimes even months. Additionally, manually deployed test environments were often misconfigured or so different from production that, even if the code passed all pre-deployment tests, it still led to problems in production.
Providing developers with on-demand production-like environments they can run in their own workstations, is a key part of CI/CD. Why is this important? Developers can only know how code will behave in production if they deploy and test it under the same conditions.
If the test code in a different environment, they may discover incompatibilities when code is finally deployed in production and then it’s far too late to fix issues without impacting customers.
Immutable Infrastructure: Cattle versus Pets
When discussing version control systems, we touched upon the need to codify environments with all other application artifacts, let’s talk about those environments more specifically.
When environment specifics are defined and codified in version control, replicating environments when capacity increases (horizontal scaling) is as simple as pushing a button (although today it’s likely automated through Kubernetes).
With the elasticity of the cloud, scaling has become increasingly important. Scaling means increasing compute capacity during peak hours. Netflix usage, for instance, peaks every Friday evening and then normalizes again sometime after midnight. To ensure buffer-free video enjoyment, Netflix replicates its streaming components, codified in version control, to match the demand. Then, all so-called replicas are destroyed bringing streaming capacity back to normal.
To enable this it’s critical that, whenever an infrastructure or application update is implemented, it be automatically replicated everywhere else and put into version control. This will ensure that, whenever a new environment is created, it will match the environments throughout the pipeline (from dev to QA to prod).
If, for instance, Netflix were to update its streaming services but forgot to capture the change in version control, it would replicate faulty or outdated components during peak hours, leading to issues, possibly even service disruption.
Since mastering the codification of environments in version control, it is not a best practice to manually alter environments as anything that is manual is also prone to error. Instead, changes are put into version control and the environment (and the code) are recreated from scratch.
This is called immutable infrastructure. These are the same set of principles discussed in the CI/CD section, applied to infrastructure.
You may have heard the cattle versus pets analogy. This is where it fits in. Previously, infrastructure was treated as pets.
If there was an issue, you did everything in your power to fix it so it would survive. Today, infrastructure is treated as cattle. If it’s not working properly or an update is needed, you kill it and spin up a new environment. This is incredibly powerful and has dramatically reduced the risk of issues sneaking into the system.
Decoupling Deployment from Releases
Traditionally, software releases are driven by marketing launch dates. The new feature to be released is thus deployed into production the day prior to the announced date. However, we know that releasing features or updates into production is always risky, especially if you release an entire feature at once.
Hence, tying deployment to the release is setting IT up for failure. Imagine the panic of the IT team if a significant problem occurs the day prior to a launch that was widely promoted creating high expectations among customers and the media.
A better approach is to decouple deployment from release. While often used interchangeably, they are two separate processes. Deployment means installing a software version to any environment, including production. It doesn’t necessarily have to be associated with a release. A release, on the other hand, means making a new feature available to your customer base.
The goal of frequent production deployments throughout feature development is to reduce risk, a process owned and driven by IT. When to expose new functionalities to customers, on the other hand, should be a business, not a technical decision.
Long deployment lead times will dictate how frequently new features can be released. If IT can deploy on-demand, how quickly to expose new functionality becomes a business and marketing decision.
Conclusion
In summary, CI calls for code to be integrated into the codebase continuously to catch errors as they occur, minimizing re-work. To implement such an approach, three tools are needed: Version control, to track all changes and make the latest source code version available to the entire team; a master branch into which developers, who work on their own branch, merge updates daily; and the deployment pipeline which will trigger a series of tests — basically automating QA.
CD extends CI to validate that code is in a deployable state and automatically releases it into production if it does. Achieving this requires a mature DevOps organization, one that has mastered CI before venturing into CD.
When implemented well, CI (/CD) will significantly increase the productivity of your IT team. Your system or application is continuously improving while deployment risk is minimized, reinforcing a positive vicious cycle of productivity and employee satisfaction. Innovation is fueled as new features and updates are pushed out quickly bringing value to users faster and more frequently. The benefits go on and on.
Clearly, as more organizations adopt these DevOps methodologies, the pressure on those who don’t increase since it’s not possible for a traditional approach to compete with CI/CD.
We hope this tutorial has helped you in learning more about Continuous Integration and Continuous Delivery (CI/CD). It’s not as difficult as you think it. Just go through the entire process once and practically implement it. Also, in case of any queries, you can contact InApps. We would love to help you.
FAQs
Why is it important to decouple deployment from release?
Decouple deployment from the release leads to a chain reaction composed of a fast feedback loop, frequent and small deployments, and safe releases. Working with complex systems is difficult and in some cases unpredictable: decoupled deployments let Software Engineers fail fast and safely. The final goal is to reduce unknown variables and give the freedom to innovate without friction.
How to resolve merge conflicts in Azure DevOps?
- To solve the conflict go back to Visual Studio and place yourself on the master branch.
- Now right-click on master and choose ‘Merge From…’ and pick feature-branch as your source and master as the target.
- Now Visual Studio will tell you there’s a merge conflict.
- Solve any conflicts.
What happens at the quality assurance workstation?
Quality Assurance (QA) refers to the process of creating deliverables, which can be carried out by a manager, client, or even a third-party reviewer. Process checklists, project audits, and the development of methodology and standards are all examples of quality assurance.
Quality assurance enables better control of the application’s quality, facilitates the evaluation of the product’s compliance with the original requirements, and provides valuable insights into end-user perceptions of the product.
Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.






