












- Home
- >
- DevOps News
- >
- Chaos Engineering Made Simple – InApps Technology 2022
Chaos Engineering Made Simple – InApps Technology is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn Chaos Engineering Made Simple – InApps Technology in today’s post !
Read more about Chaos Engineering Made Simple – InApps Technology at Wikipedia
You can find content about Chaos Engineering Made Simple – InApps Technology from the Wikipedia website
Chaos engineering as a discipline has already enabled many organizations to instill a culture of prioritizing resiliency into every single aspect of their services. Testing and addressing issues as early as possible in the DevOps life cycle is a key practice that every engineering team upholds, since even a single failure can render entire services unavailable and cause irrevocable losses. Chaos engineering assists in discovering these hazardous issues before they can cause a failure in production.
The cornerstone of every chaos engineering practice is constituted out of chaos experiments, which help hypothesize about a certain kind of failure that might adversely affect any service. It’s always crucial to emphasize the right kind of experimentation, to simulate real-life failure scenarios that can affect a target service. A very important consideration in this process is that your distributed system is an assortment of several dependent services, all of which contribute to your service’s resiliency.
Successful chaos engineering practitioners come to master the skill of fabricating every chaos experiment on a case-by-case basis, to leverage the most results out of each experimentation.
Cloud Native Resiliency
The shift toward cloud native technologies has enabled the development of more manageable, scalable and dependable applications, but at the same time it has brought about unprecedented dynamism to critical services. This is due to the multitude of coexisting cloud native components that have to be managed individually. Failure of even a single microservice can lead to a cascading failure of other services, which can cause the entire application deployment to collapse.

Hence, it is paramount for your chaos engineering practices to conform to a cloud native way of designing, orchestrating and analyzing chaos in the target environments. More definitively, cloud native chaos engineering ensures that every component responsible for an entire application’s proper functioning is resilient and capable of sustaining real-life turbulent conditions. This requires orchestrating chaos on the scale of the entire application, rather than a specific microservice. Therefore, it’s crucial to have access to a diverse set of chaos experiments that can target every aspect of your application. This includes targeting the allocated resources, the software stack and the underlying infrastructure for all possible business use cases.
The Litmus Suite of Chaos Experiments

Neelanjan Manna
Neelanjan is a software engineer at ChaosNative. He is a contributor to the CNCF LitmusChaos project, a chaos orchestration framework for practicing chaos engineering in cloud native environments.
LitmusChaos was created with the primary goal of performing chaos engineering in a cloud native manner, scaling it as per the cloud native norms, managing the life cycle of chaos workflows and defining observability from a cloud native perspective.
Chaos experiments help achieve this goal by injecting chaos into the target resources, using simple, declarative manifests. These Kubernetes custom resource (CR) manifests allow for an experiment to be flexibly fine-tuned to produce the desired chaos effect, as well as contain the experiment blast radius so as to not harm other resources in the environment. Every chaos experiment ensures a safe chaos rollback to restore the target resources to their original state after the chaos interval.
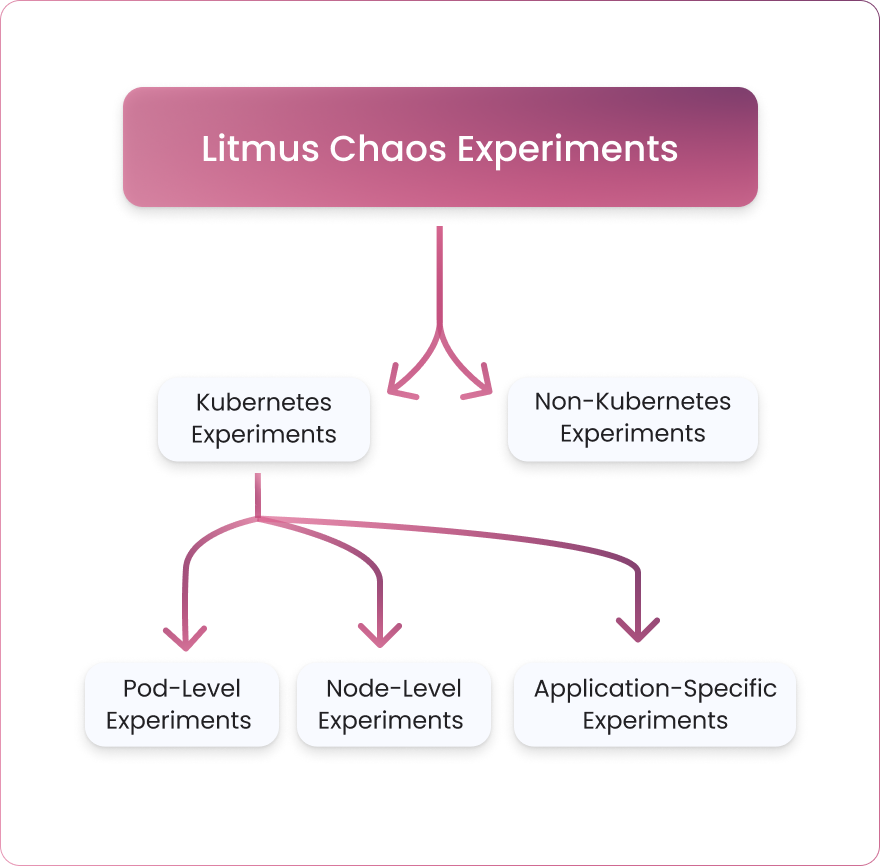
There are more than 50 Litmus chaos experiments that can be broadly categorized into two categories:
- Kubernetes experiments
- Non-Kubernetes experiments
Kubernetes experiments can be further divided into:
- Pod-level experiments
- Node-level experiments
- Application-specific experiments
Pod-level experiments inject chaos on the application level by typically depriving the application of some dependent resource, such as CPU, memory, network, IO, etc. Some of the examples include pod delete, pod DNS error, etc.
Node-level chaos experiments target the underlying Kubernetes deployment infrastructure. They tend to have a higher blast radius and affect more than one application deployed on the Kubernetes cluster. Some examples include node CPU hog, node memory hog, etc.
Application-specific experiments render a failure scenario pertaining to a given application deployed in a cloud native environment, such as Cassandra pod delete experiment, Kafka broker pod failure, etc.

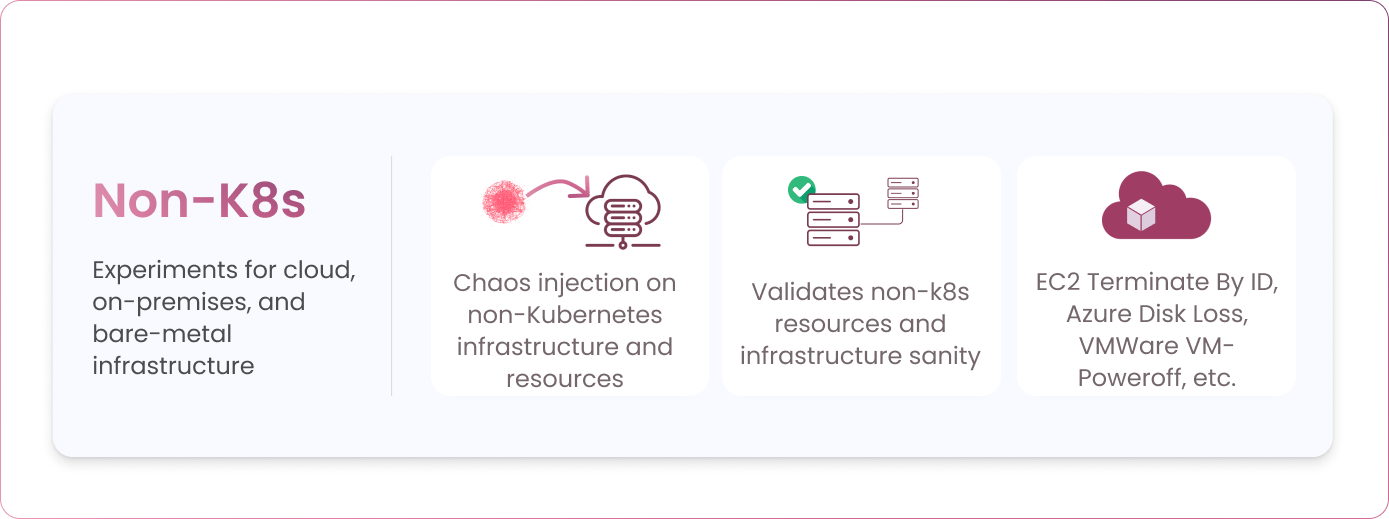
Non-Kubernetes experiments typically target public cloud infrastructure resources, such as AWS, Azure and GCP, on-premises VMWare infrastructure and even bare-metal servers. Non-Kubernetes chaos experiments are especially helpful for validating the entire application resiliency, even when your cloud native services coexist with existing critical services that are a part of the traditional technology stack. Examples include EC2 Terminate By ID, Azure Disk Loss, VMWare VM-Poweroff, etc.
Litmus chaos experiments also support BYOC (bring-your-own-chaos), which lets you integrate any third-party tooling to perform the fault injection. They can also be paired with Litmus Probes to automate the process of validating the resource state before, during and after the chaos interval.
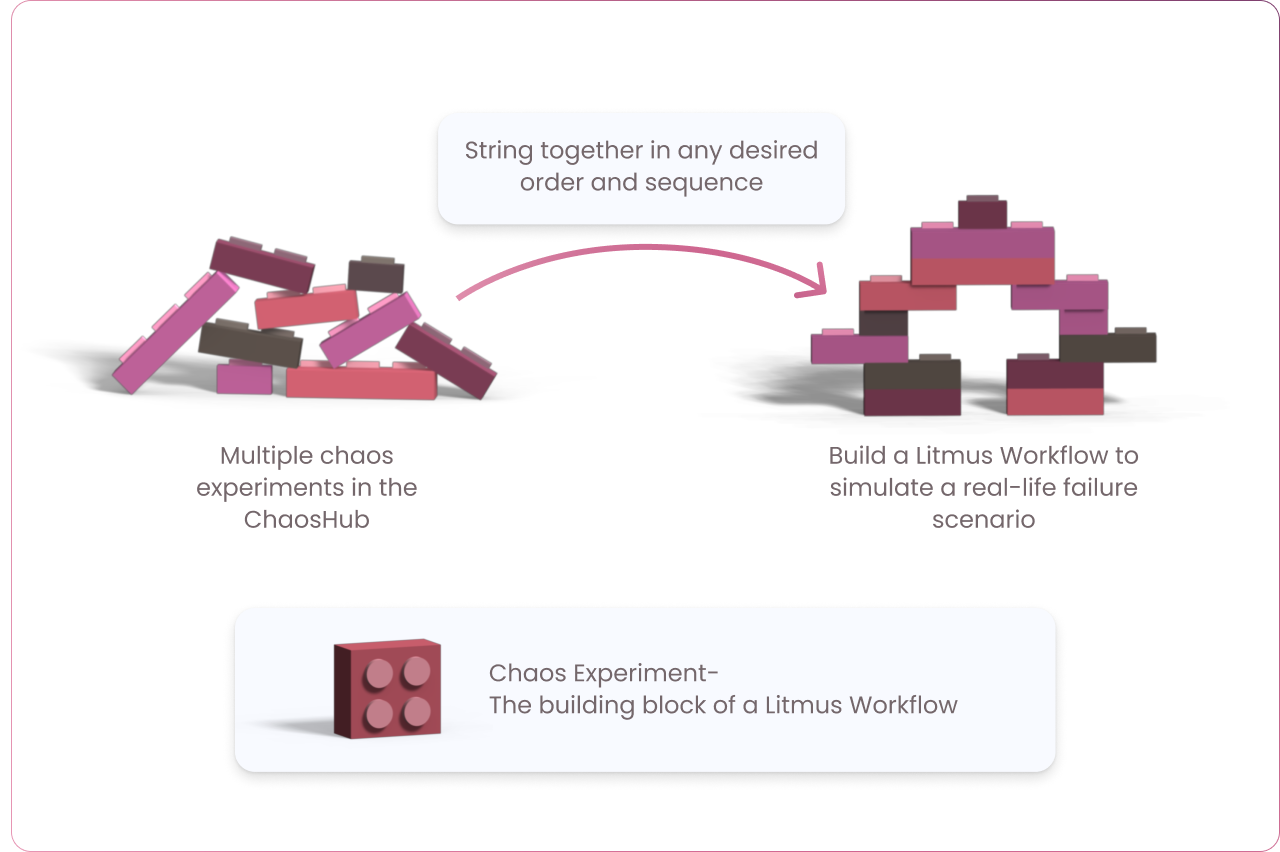
Chaos experiments serve as the building units for chaos workflows, which string together multiple chaos experiments in any desired order and sequence to inject failure into more than one resource. This allows for the creation of complex, real-life failure scenarios involving several different aspects of the entire application as part of a single workflow, simply using the ChaosCenter web UI. Think of chaos experiments as Lego blocks encapsulating failure conditions for a specific target resource. These Lego blocks can be flexibly arranged in any desired order to shape the chaos workflow, a conglomeration of failure scenarios tailored to validate your specific service-level objective (SLO) requirements.
You can also define your own chaos experiments with ease, using the Litmus SDK. This provides a simple way to bootstrap your chaos experiment for Litmus by creating the different requisite artifacts based on the given experiment information. Therefore, it simplifies the process of development of the chaos experiment, where developers are responsible for only adding the experiment’s business logic. Litmus SDK is available for Golang, Python and Ansible, which allows developers to develop their chaos experiments in whichever language they prefer.
Litmus also features ChaosHub, an open source marketplace hosting all the different chaos experiments offered by Litmus to simplify the process of discovering, fine-tuning and executing chaos experiments. You can also have your own private ChaosHub, which helps in maintaining custom chaos experiments for an organization that isn’t part of the open source ChaosHub.
Summary
Pioneering cloud native chaos engineering at scale has been one of the fundamental goals of the LitmusChaos project, and Litmus’ chaos experiments have been molded out of the same vision. In a world where entire application stacks and architectures are upgrading at the pace of hours and minutes for a much-required competitive edge, cloud native chaos engineering promises resilient services for every organization. Litmus continues to evolve in an attempt to further diversify its list of chaos experiments for Kubernetes, cloud infrastructure and application-targeted chaos experiments , all the while pioneering its cloud native principles for chaos engineering.
LitmusChaos is simple to deploy on your Kubernetes cluster or namespace. Litmus is available as a SaaS at ChaosNative Litmus Cloud and comes with a forever-free plan. Sign up at litmuschaos.cloud for a super-quick start on chaos engineering or follow the Litmus docs to install Litmus on your own Kubernetes cluster.

Chaos Engineering Community Conference
Finally, ChaosNative hosts an annual chaos engineering conference called ChaosCarnival. Global chaos engineering experts, enthusiasts and practitioners speak at this conference to share their experiences, best practices and success stories. Register for free to get updates on the conference.
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.














