












- Home
- >
- DevOps News
- >
- Chaos Engineering for Every Layer – InApps 2022
Chaos Engineering for Every Layer – InApps is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn Chaos Engineering for Every Layer – InApps in today’s post !
Read more about Chaos Engineering for Every Layer – InApps at Wikipedia
You can find content about Chaos Engineering for Every Layer – InApps from the Wikipedia website
As chaos engineering undergoes increasing popularity, German IT consulting firm Codecentric has spun off chaos engineering startup Chaosmesh.
Benjamin Wilms, together with Dennis Schulte and Johannes Edmeier, launched Chaosmesh last October with backing from Codecentric, their former employer, and its founder and former CEO Mirko Novakovic.
Wilms previously released Chaos Monkey for Spring Boot in April 2018 and Edmeier is that project’s administrator.
Netflix originally developed its Chaos Monkey tool back in 2011, which it described as “a tool that randomly disables our production instances to make sure we can survive this common type of failure without any customer impact.”
The original monkey has spawned a whole army of simian-monikered tools, and a host of competitors since have jumped into the market.
InApps has talked to early adopters about the benefits of chaos engineering and the ways to measure its benefits to the business side, as well as its specific application to Kubernetes to improve reliability.
https://www.youtube.com/watch?v=ln1eANzbiCw
The APM startup Instana also grew out of Codecentric in April 2015.

Chaosmesh is not to be confused with the chaos engineering platform with the same name — spelled “Chaos Mesh” — from China’s PingCAP, creator of the TiDB database.
Like the cloud native Litmus framework, Chaosmesh focuses on Kubernetes. PingCAP touts “all-around fault injection methods for complex systems on Kubernetes, covering faults in Pod, network, file system, and even the kernel.”
The German Chaosmesh has a wider focus.
“We are injecting chaos on the infrastructure layer, on the platform layer like AWS, Azure Kubernetes, Docker, and also on the application stack,” Wilms explained.
“And normally, for this, you need to install some special tools, or you have to get some root access on the machine and so on. And you need, of course, the guy from ops… With our core platform, you are able to inject all kinds of latency network drops or exceptions in the application stack,” Wilms said.
“Your systems are constantly changing: New versions are going into production, hardware is being replaced, firewall rules are adapted and servers are restarted,” according to a company blog post that points out potential problems such as:
- Failure of a node in a Kafka cluster
- Dropped network packets
- Hardware errors
- Insufficient max-heap-size for the JVM
- Increased network latency
- Malformed responses
It adds that chaos shouldn’t come as a surprise, your aim is to prove a hypothesis with controlled tests that help. you understand your distributed systems better.
“Our agents are running on virtual machines or inside of Docker or Kubernetes, and all agents are able to do auto-updates. So for example, if we are developing new attacks on new discovery features, our agents will install this automatically so you don’t need to patch it again,” Wilms said. “Our agents inside able to detect where they are installed.
“So for example, the agent is able to do some auto-discovery processing. If I’m running inside of a Docker Swarm or this agent is running inside of Kubernetes, all this data will be collected into our central platform, which can be installed on-prem also.”
It also offers role-based access control on target level. So, for example, if you have a container, you can limit access so that not everybody can kill this specific host.
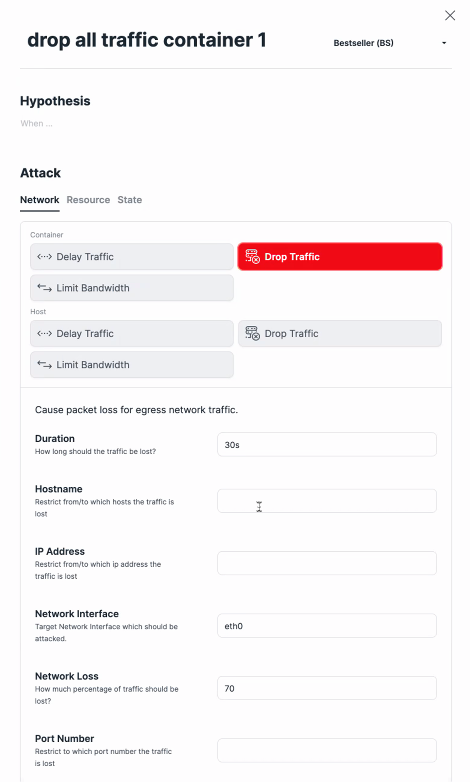
On the platform, you can set up attacks on network components, delay traffic in containers, delay traffic on a specific host. You can drop traffic, limit bandwidth. You also can set a specific blast radius.
“You can set your blast radius so you can say, ‘I know it’s all running in US East number one, so please drop all traffic that is inside of US number one on AWS.’ Or you can limit the blast radius by selecting a specific Docker name. … We can pause a container inside of Kubernetes or vanilla Docker. You can also kill a pod.”

Gremlin leads the pack of commercial software-as-a-service (SaaS) offerings for chaos testing, but there are a growing lists of tools, including ChaosIQ, New Relic’s Chaos Panda and Shopify’s ToxiProxy as well as the array of simian-named tools that Netflix has open sourced.
“We are able to run our platform as software-as-a-service. You can run our agent inside your applications and your stack. You can run it on-prem in your own data center, because here in Europe, there are many regulations and some restrictions. You’re not allowed to do some chaos things in the SaaS environment. … This will make our market much, much bigger than if we are just offering SaaS, especially in Europe,” Wilms said.
Image by Steven Liao from Pixabay.
InApps is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Docker.
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.














