












- Home
- >
- DevOps News
- >
- Chaos Engineering for Cloud Native – InApps Technology 2022
Chaos Engineering for Cloud Native – InApps Technology is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn Chaos Engineering for Cloud Native – InApps Technology in today’s post !
Read more about Chaos Engineering for Cloud Native – InApps Technology at Wikipedia
You can find content about Chaos Engineering for Cloud Native – InApps Technology from the Wikipedia website

Uma Mukkara
Uma is CEO of ChaosNative and a maintainer of the LitmusChaos project.
In today’s e-commerce world, customer retention, customer acquisition and customer satisfaction are top priorities of management, whether it is the operations, business or product engineering team. Service reliability is key to your business success. While this is obvious, service reliability has become more important in recent times. The reason is simple: More people are using digital services and businesses have become digital-centric. This digital transformation is one of the reasons we are seeing server administrators, database administrators and network administrators becoming site reliability engineers (SREs). The move to microservices and containerization of applications also is fueling this transformation.
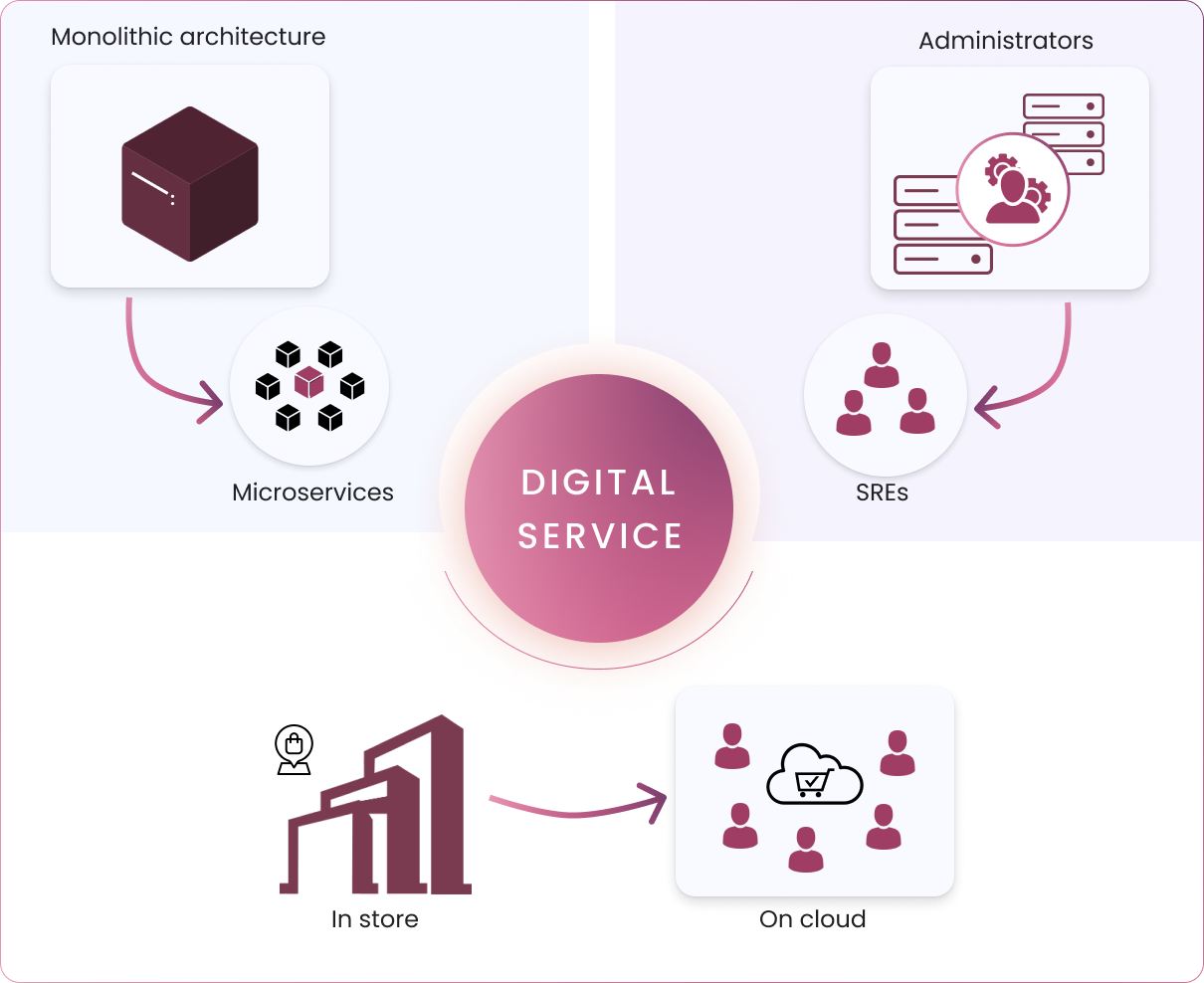
Digital transformation making service reliability a key business requirement
What Is Service Reliability?
The most common answer is: No outages or very long uptimes. However, we all know that outages are inevitable at some point. So service reliability is really about reduced outages. In addition, services get upgraded from time to time, so continuity of service availability during upgrades is also a key requirement. If you consider service outages as eventually inevitable, an optimal way to think of service reliability is to create a situation where business impact is minimal when a service outage happens. A service outage should not happen frequently, but when it does, quick recovery helps minimize damage to user experience.

Service reliability
Service reliability depends on multiple factors, such as application stability, performance at scale, performance at load, underlying infrastructure and the ability of applications to withstand a failure in any one of multiple components involved in providing the service.
Challenges in Cloud Native
IT is moving to cloud native. In a cloud native environment, there are a lot of moving pieces. You will have many infrastructure and middleware software components that come in handy when you build a service in cloud native. The main difference between a cloud native service versus a traditional one is that with cloud native you are dealing with many more components — sometimes multiple times more components — each of which are independently well-tested and stitched together. So, how does this affect service reliability? You might think that these services are naturally more reliable because of well-tested microservices, but you will be surprised how often this is not the case. The reason is that your primary application on which a service is running might not fare well when faults happen in the dependent components.

Cloud native & Reliability
As shown in the above diagram, in cloud native, the application that defines your service is making up only about 10% of the code in the entire stack. Reliability for that app requires the rest of the stack to be stable and work together when faults occur. Any fault or multiple faults happening in the stack should not impair service availability. This defines how good your service reliability is.
The other factor that contributes to the service reliability in cloud native is how fast changes are happening in cloud native DevOps. Containerization and advancements in continuous integration/continuous deployment (CI/CD) systems, along with the organizational push to release faster, are some of the reasons microservice release times are frequent. They have moved from quarterly to monthly to weekly, and in some cases multiple times in a week. This means you are releasing code faster, and the dependent code in your service is also going through continuous upgrades. In cloud native, something is always being upgraded. This makes it difficult to ensure that service reliability is kept at the desired level.
The above two areas show the need for service reliability in cloud native. Fortunately, if you invest in a structured approach known as chaos engineering, service reliability can definitely be achieved. Chaos engineering is an important science now more than ever. While chaos engineering’s roots go back to 2011, only in the past couple of years has it attained prominence, primarily driven by cloud native service deployments becoming more common.
Chaos Engineering 101
In simple terms, chaos engineering is about collecting, designing, implementing, orchestrating and scaling the faults in various applications and the infrastructure of a service. It is about engineering the faults around a service in a controlled way, to validate the resilience of the service and find any weaknesses. Chaos engineering has been thought of and advocated in many other forms — testing in production, breaking in production, etc. But to me, it is engineering around chaos; it is a continuous process and all principles of engineering need to be applied to chaos as well.
There is some hesitance to adopt chaos engineering into Ops or DevOps, which is to be expected. After all, it requires breaking things. However, a new school of thought is to start chaos at the beginning: Consider it as part of your service build-up, so it gets embedded into your delivery process or DevOps. Some new implementations of cloud native DevOps consider chaos engineering a structural and integral part of their testing or CI/CD. This scenario is going to become increasingly common as more success stories emerge.
So, let’s define chaos engineering one more time, but technically. Chaos engineering is the science of designing a fault along with a steady-state hypothesis, orchestrating the fault and validating the steady-state hypothesis. Steady-state definition and validation of it sometimes are more important than the introduction of a fault. Steady-state definition could vary slightly from team to team, and from time to time based on the load conditions and other state variables of the service. The easiest way is to associate the steady-state with the service level objectives (SLOs) at that time and validate them. To summarize another way, chaos engineering can also be considered continuous validation of the SLOs under random fault injections into the dependent applications or the infrastructure of a service.

Chaos Engineering
Cloud Native Chaos Engineering 101
We have discussed the need for chaos engineering in cloud native and considering it from the beginning rather than an afterthought. Now let’s discuss how you can practice chaos engineering more effectively in cloud native, what I call “cloud native chaos engineering” or CNCE. The cloud native definition includes some mandatory principles, such as requiring declarative config, being flexible, scalable, across multiple clouds, using declarative APIs, etc. All these principles are applied broadly when you practice cloud native chaos engineering. We have been advocating the following as principles of cloud native chaos engineering for the past three years.
Principles of Cloud Native Chaos Engineering
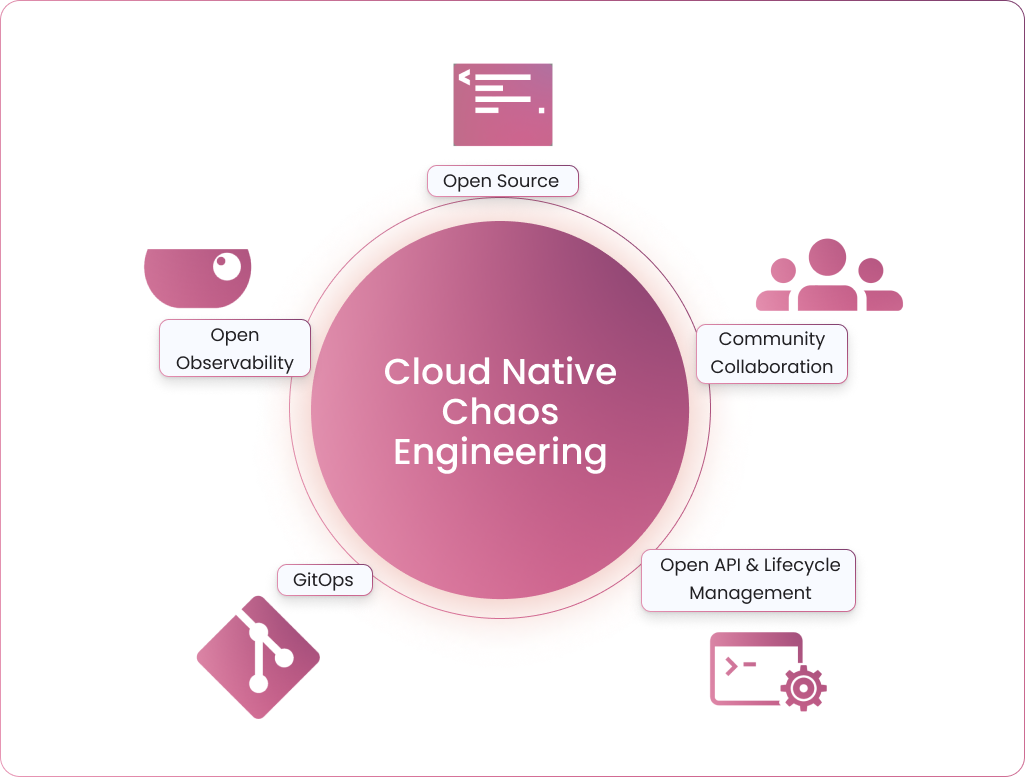
Cloud Native Chaos Engineering principles
Open Source
Cloud native communities and technologies have been revolving around open source. Chaos engineering frameworks being open source in nature benefit in building strong communities around them and help them make them more comprehensive, rugged and feature-rich.
Chaos Experiments as Building Blocks
Chaos experiments need to be simple to use, highly flexible and tunable. Chaos experiments have to be rugged, with little or no chance of resulting in false negatives or false positives. Chaos experiments are like Lego blocks: You can use them to build meaningful chaos workflows.
Manageable Chaos Experiments and API
Chaos engineering has to employ well-known software engineering practices. Managing chaos scenarios can quickly become complex, with more team members getting involved, more changes happening frequently and the requirements being altered. Upgrading chaos experiments becomes common. The chaos engineering framework should enable management of chaos experiments in an easy and simple manner, and should be done in the Kubernetes way. Developers and operators should think of chaos experiments as Kubernetes customer resources.
Scale Through GitOps
Start with low-hanging fruit in terms of obvious and simple issues. As you start fixing them, chaos scenarios become more comprehensive and large; the number of chaos scenarios also increases. Chaos scenarios need to be automated or need to be triggered when a change is made to the applications of the service. Tools around GitOps may be used to trigger chaos when a configuration change happens to either application or chaos experiments.
Open Observability
Observability and chaos engineering go together when fixing issues related to reliability. There are many observability stacks and systems that are well-developed and put into practice. Introduction of chaos engineering should not require a new observability system. Rather, the context of chaos engineering should fit nicely into the existing system. For this, chaos metrics from the system where chaos is introduced are exported into the existing observability database, and the context of chaos is painted on to the existing dashboards.
Litmus Is Built for Cloud Native
LitmusChaos is built with the cloud native chaos engineering principles mentioned above as its foundational architectural goals. Litmus is a complete chaos engineering framework built as a cloud native application. You can use it to build, orchestrate and scale chaos experiments seamlessly. Litmus comes with a bunch of ready-to-use chaos experiments hosted on an open hub called ChaosHub. These experiments form the basis for Litmus workflows, which can be closely compared with your actual chaos scenarios. SREs, QA and developers collaborate to build the required chaos workflows and orchestrate them using GitOps for scaling, as well as to trigger chaos upon a configuration change to the deployments.

Litmus overview
Chaos Engineering Made Easy
LitmusChaos is simple to deploy on your Kubernetes cluster or namespace. Litmus is hosted at ChaosNative Litmus Cloud as SaaS and comes with a forever-free plan. Sign up at litmuschaos.cloud for a super-quick start on chaos engineering or follow the Litmus docs to install Litmus on your own Kubernetes cluster.

Litmus on cloud
Chaos Engineering Community Conference
ChaosNative hosts an annual chaos engineering conference called ChaosCarnival. Global chaos engineering experts, enthusiasts and practitioners speak at this conference to share their experiences, best practices and success stories. Register for free to get updates on the conference.
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.











