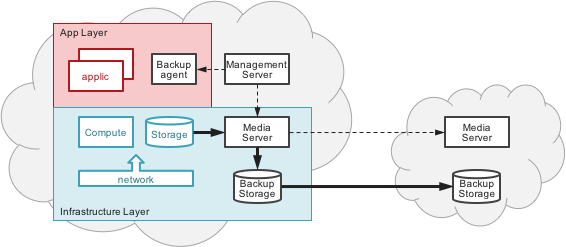
The notions of control plane and data plane have always existed even in the data protection space, albeit typically referred to as the “management and policy layer” versus the “media server layer” in a storage integrated data protection solution.
And while such backup solutions solved the traditional data center backup to tape, and eventually disk, really well, the solution does not readily translate into a distributed multicloud solution. That’s where a data protection solution requires cloud-scale, multiprovider integration with clear separation of control, data movement and multitier data storage.
The separation not only provides independent scaling at the control and data level, but also creates the opportunity for vendor or cloud provider independence. Additionally, the separation of data plane services allows the solution to leverage all current and future innovations around data movement, data copy and storage optimizations that the cloud storage provides natively.
Let’s explore the inherent shortcomings of traditional data protection architectures and then illustrate the clear advantages of a control plane-centric approach to backup and recovery and data management for multi-cloud environments.
Traditionally, a storage integrated data protection solution focuses on controlling and optimizing data movement and data persistence within the media server. This is done to optimize streaming throughput, network bandwidth utilization, and inline de-duplication.
The key focus of such a solution is to minimize application “down” time in the event of a logical error or physical server failure. Since protection and recovery was merely a function of storage level backup of the block volume or file-system, it made sense to have the end-to-end solution in the storage infrastructure layer.
Backup performance was determined by the connectivity and I/O throughput of the media servers to storage appliances. Scaling then became a function of adding more media servers and associated secondary storage to handle more and larger data streams.
Multiple factors in the cloud era will also diminish the effectiveness of a storage integrated data protection and data management solution. In many cases, the cloud provider (in both public and private instances) abstracts and virtualizes the storage infrastructure behind the de-facto file and object storage standards. This is making it harder, if not impossible, to establish a common data model and data movement interface for protection purposes.
Cloudy Outlook
So how does a storage integrated data protection solution overcome these limitations in a cloud environment?
In order to move or replicate protection data copies from the data source to a destination protection store, the vendor typically has to provide a media server instance in the cloud. The media server model doesn’t leverage and isn’t optimized for the storage capabilities of the cloud storage provider (including de-duplication, replication, storage distribution, etc.). Moreover, the backup images behind a media server are in a proprietary format that cannot be easily used for recovery of an application instance in the remote recovery environment without another instance of the media server.
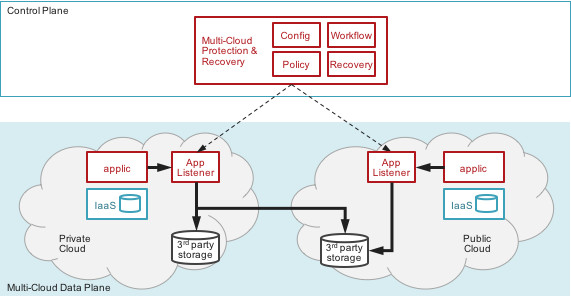
A distributed control plane architecture avoids the problems of integrating the control and data plane while delivering key advantages of scaling across multiple clouds.
As shown below, the distributed control plane for data protection can span multiple different cloud environments and hybrid deployments. Protection configuration, policies and workflows are centrally maintained and controlled. Data replication within or across cloud environments occurs and scales independently of the control plane.
By not providing data plane functionality, the control plane architecture can take advantage of the capabilities and independent scaling of the cloud provider’s storage services. The other benefit from data plane abstraction is the extensibility into new applications and persistence services. Without significant changes to the control plane, new application or persistence models can be supported in the data plane, while leveraging its specific scaling models.
Our own Datos IO CODR architecture largely adheres to the above architecture with some notable additional advantages. The architecture leverages current and next-generation database internal replication capabilities to extract protection copies that can be persisted in standard file or object storage. Beyond that, Datos IO RecoverX provides an industry-first semantic de-duplication process that introspects into data for maximal storage efficiency.
For recovery purposes, the CODR engine supports configuration-oblivious restore via deep indexing of each snapshot. Parallel data copies to appropriate restore nodes allows for a lazy database refresh to complete an application-level restore.
As stated at the onset, a customer’s journey to the cloud requires a new approach for data protection, data recovery and data management in general. Datos IO’s control plane architecture provides the key benefits around the multicloud, multivendor support with independent scaling of protection and recovery storage, application awareness and as a result, creates application and operational mobility across the multicloud.
Feature image via Pixabay.