
InApps is a Vietnam-based Offshore Development Center building dedicated, AI-augmented engineering teams for CTOs in the US, UK, and Australia. Built for long-term product ownership, not outsourcing
Trusted by engineering teams across 15+ countries
From startups to Fortune 500 companies


















Why Vietnam with InApps
Most offshore engagements fail at the team, not the tech. InApps is built differently: dedicated engineers, AI tooling in every sprint, and a Vietnam-based operation held to Western engineering standards. Most clients that start with us are still with us years later.
Your engineers work exclusively on your product. No shared resources, no revolving door of contractors.
Claude, Cursor, and GitHub Copilot built into every sprint as standard practice, not an add-on you pay extra for.
ISO 27001 certified. Senior talent. 85%+ multi-year retention. GMT+7 with flex hours for AU and US morning standups.


 5.0★Clutch Rating
5.0★Clutch Rating
How we work
Your engineers work exclusively on your product, never shared across other clients. Most partnerships started as a single build and have run continuously for years, because the team understands your product well enough to shape the roadmap, not just close tickets.
Every InApps engineer works with Claude, Cursor, and GitHub Copilot built into their daily workflow, across coding, code review, and documentation. Standard practice from day one, not an optional add-on you pay extra for.
Most offshore vendors assign your team for you. At InApps, you run the final interview and no engineer joins without your sign-off. You talk straight to the people writing your code, with no vendor PM layer in between.
AI in Practice
Not a buzzword and not an upsell. The same AI tools you'd expect a modern engineer to use are standard across every InApps team, in every sprint.
Engineers pair with AI in the editor to scaffold, refactor, and move faster on routine work, so senior time goes to architecture and hard problems, not boilerplate.
AI-assisted review runs on every pull request to catch bugs, edge cases, and security issues early, alongside (never instead of) human review from senior engineers.
Specs, changelogs, and onboarding docs are drafted with AI and verified by the team, so your codebase stays documented and knowledge never walks out the door.

What we build
Web apps, APIs, and platform engineering with dedicated senior teams.
Custom agents, RAG pipelines, and LLM integrations built with LangGraph and AutoGen.
A fully managed engineering team dedicated exclusively to your product.
Senior engineers embedded into your team in days, not months.
Codebase review, architecture assessment, and tech debt clean-up with a written report.
Tech Stack
Case Studies
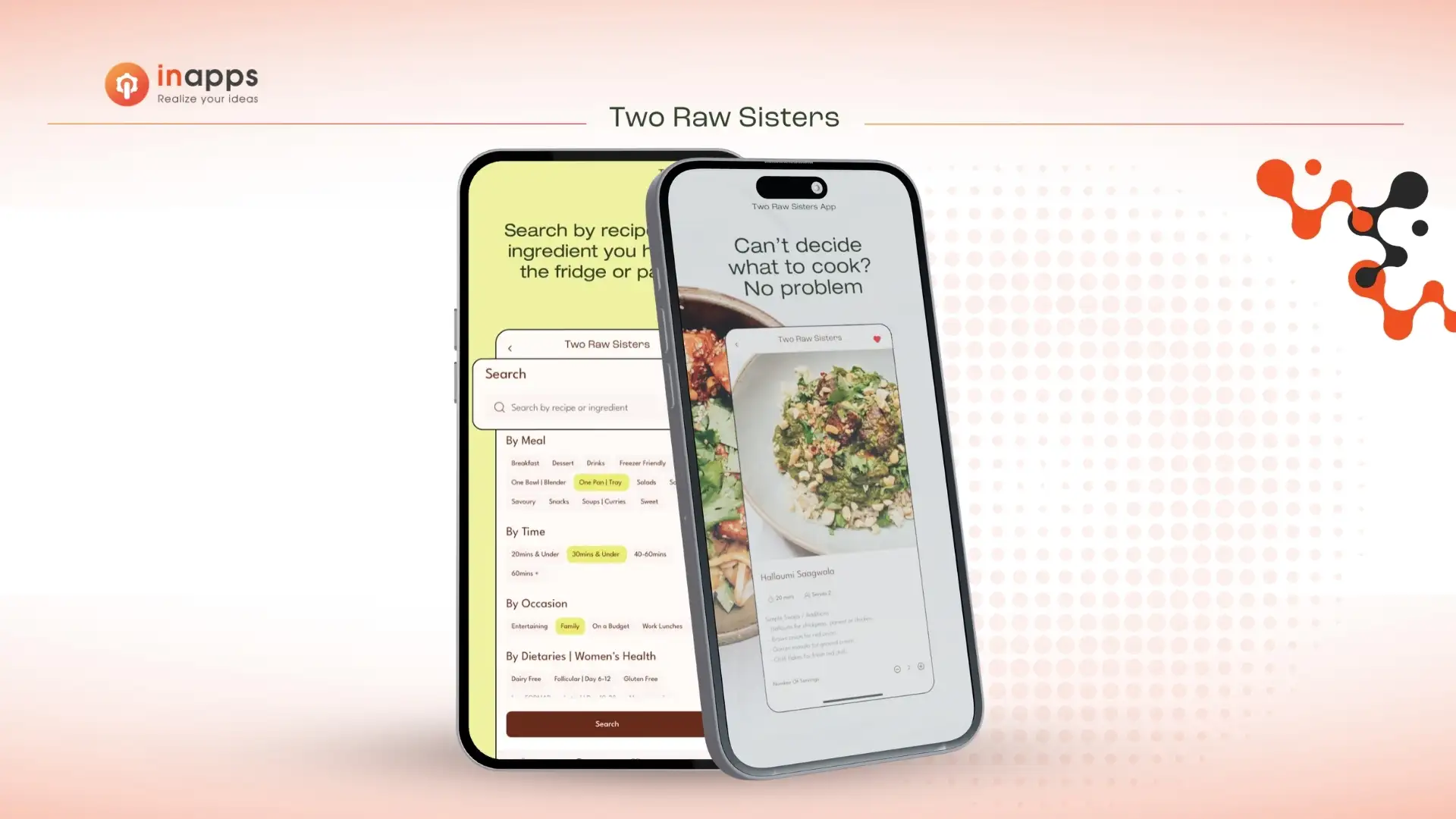
See how InApps rescued Two Raw Sisters' undocumented app after a failed vendor handoff, fixing critical bugs and managing it ever since.
Engagement Models
All models include dedicated engineers, full transparency, and no hidden fees.
DEDICATED TEAM
Best for: long-term product teams
A full engineering team working exclusively on your product, managed, retained, and ready to own your roadmap.
STAFF AUGMENTATION
Best for: filling specific skill gaps fast
Engineers who embed directly into your team, productive from day one, no HR overhead, flexible scale.
PROJECT-BASED
Best for: MVPs and defined-scope builds
End-to-end delivery on a defined scope, milestone billing, with a dedicated PM running every sprint.
MANAGED SERVICES
Best for: ongoing operations and reliability
We run and maintain your product end to end: monitoring, SLAs, and continuous improvements included.
Testimonials
“They don't just build what you ask for. They think about the end result, and then go beyond it.”
“On time. Every time. And when I had questions, any questions, they were answered in full. That's not common.”
“Quality engineers, proposed within days. But what actually made the difference was the culture fit, they worked like they were part of our team from day one.”
Getting Started
No lengthy procurement. No months of interviews.
Day 1–5
30 minutes. A solutions architect maps your stack and tells you exactly what your team would cost before you commit to anything.
Weeks 1–3
We shortlist candidates in 3–5 days, matched to your tech stack. You interview every engineer. No one joins without your sign-off.
Weeks 4–6
Engineers join your Slack, GitHub, and standups from week one. No PM layer. Most teams push their first commit by week 4.
Common Questions
We can have your team ready within 2 weeks of the first call. Our pre-vetted talent pool means no lengthy recruitment cycles - just fast, reliable onboarding.
Recognition
Recognized by the world's leading B2B review and research platforms
No commitment. Free 30-min discovery call to scope your project and meet your first engineer.










