












- Home
- >
- DevOps News
- >
- Visualize Time-Series Data with Open Source Grafana and InfluxDB – InApps Technology 2022
Visualize Time-Series Data with Open Source Grafana and InfluxDB – InApps Technology is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn Visualize Time-Series Data with Open Source Grafana and InfluxDB – InApps Technology in today’s post !
Read more about Visualize Time-Series Data with Open Source Grafana and InfluxDB – InApps Technology at Wikipedia
You can find content about Visualize Time-Series Data with Open Source Grafana and InfluxDB – InApps Technology from the Wikipedia website
A recent survey commissioned by NGINX of some 1,825 NGINX users revealed that about 68 percent of respondents’ organizations are using or investigating microservices, and 66 percent are using or investigating containers. When you’re talking “two-thirds” of a sample pool, you’re addressing a sizable chunk.
But these are NGINX users anyway, so you have to ask what’s happening with the other one-third.
As readers of this publication know, adoption of these technologies comes at a cost. DevOps teams usually end up with even more moving parts to monitor and control than they had before. What’s more, they’re monitoring more ephemeral components, which may prompt them to use several disparate monitoring solutions.

Gunnar Aasen
Gunnar is a Support Engineer at InfluxData. He enjoys helping customers make the most of their InfluxData solutions and is responsible for the AWS architecture, automation and release management of InfluxCloud. His current programming language of choice is Go.
The partnering of two popular open source projects, InfluxData’s InfluxDB and Grafana, can help them monitor and control their cloud infrastructure, application and database instances, and containers, giving DevOps a consolidated view or single pane of glass.
InfluxData offers a time-series data platform that collects and stores metrics and events for monitoring. It includes a streaming engine, and over 100 collector agents to gather metrics from a number of sources and store them in a time-series database. This database is optimized for high write loads and large data set storage. It conserves space through downsampling, and by expiring and deleting unwanted data automatically. It also comes with an elegant UI, supporting alert thresholds that can trigger popular tools such as HipChat, OpsGenie, Alerta, Sensu, PagerDuty, and Slack.
Grafana is a vendor-neutral, open source time-series analytics platform with well over 100,000 active installations. DevOps teams turn to Grafana Labs to help bring their disparate data sources together. Its seamless integration with InfluxData makes it the ideal tool for visualizing collected metrics.
How to Set Up Grafana and InfluxDB
You can download InfluxDB and related tools from here and Grafana from here.
For InfluxData, you will need an agent to collect and store your metrics. We recommend our own Telegraf which has over 100 plugins, although you may use a traditional collection agent like StatsD.


Carl Bergquist
Carl is a core contributor to Grafana and Principal Engineer at Grafana Labs. He’s always had one foot in operations, and another in development. Carl loves watching people learn more about their systems using Grafana. He strongly believes the community as a whole can do better than any organization on its own.
The InfluxDB and Grafana processes may share the same server or the same instance. However, if you expect to have a very large InfluxDB installation, a high number of Grafana users, or if your organization has a particularly strict security posture or deployment profile, separate servers is also perfectly acceptable. InfluxDB’s API typically defaults to port 8086, and Grafana’s to port 3000. Grafana will query the InfluxDB API in order to gather data for a dashboard.
InfluxDB will be the more memory- and CPU-intensive application of the two, simply because a lot of Grafana’s work happens in a very lightweight, browser-based application.
InfluxDB-Grafana Setup Configurations
When setting up your default configuration for InfluxDB and Grafana together, you can enable query log, which will log all queries when executed or sent to the InfluxDB API. Such a log may be useful for debugging Grafana issues. Use the coordinator section of the config to set the maximum number of concurrent queries. This may help ameliorate issues with multiple Grafana users hitting InfluxDB with queries at the same time. You can also set query time-outs and log for times when queries are running slowly.
The max-select point, max-select series, and max-select buckets settings limit the number of results that can be returned. This can help stop a particularly expansive query from slowing down or taking down the InfluxDB server.
Grafana’s configuration file includes helpful settings such as http port and router logging, expediting your browser load times.
Grafana’s Security Settings
Every Grafana instance has a default admin user and password, which you’ll want to change. By default, Grafana’s registration process allows non-admin users to create organizations. So we recommend setting the “enable anonymous access” option to “false.”
If you intend to debug Grafana — and you will — definitely bump up the log level to debug. Grafana will expose metrics about itself. Telegraf has a Prometheus input built-in, so you can direct it towards Grafana. This way, you can collect internal metrics, put them into InfluxDB, then graph them in Grafana.
If you are using InfluxCloud and need to configure access to different groups and users on Grafana, check out this short webinar: “InfluxCloud with Multi-Tenant Grafana.” Likewise, to use the Grafana UI to set up graphs and utilize the InfluxDB Query Builder, see “How to use Grafana with InfluxDB.”
Building Dashboards and Setting Up Graphs
Grafana’s dashboards, like the one above, are sets of rows and panels that you can edit once you select InfluxDB as their data source. You can easily change how to display the graph as lines, bars, or points. Within the graphs, you can use any aggregator you like, select multiple fields, or use a transformation like moving_average.
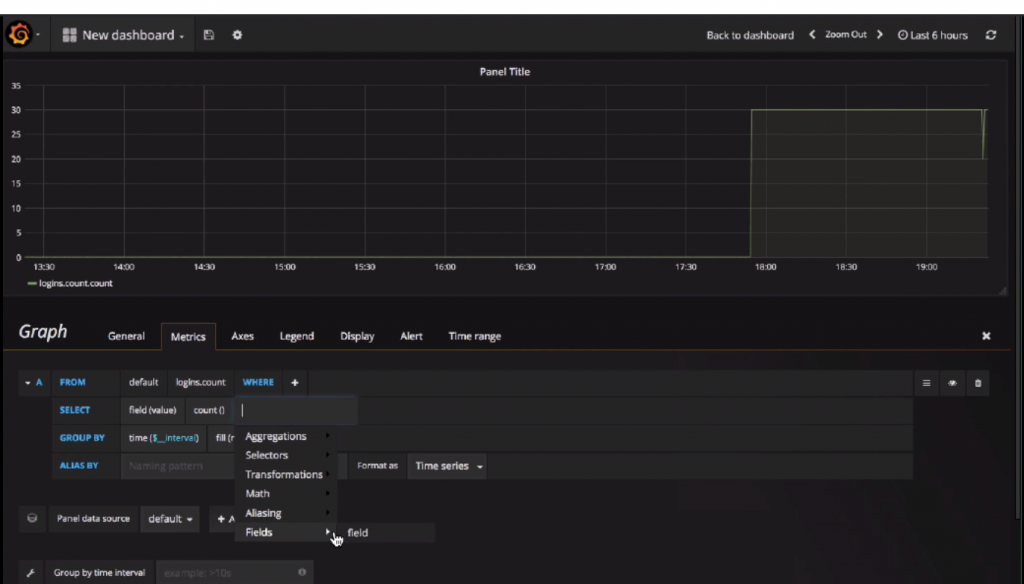
Every Grafana graph is actually a query to InfluxDB. If you have a dashboard of 30 graphs, that’s 30 queries that you’re sending to InfluxDB and 30 queries that need to get the results collated by InfluxDB, and then sent back through Grafana. Consider whether a plethora of graphs will actually be useful to you.
Although Grafana has no limitation on the number of metrics displayed on one graph, you’ll want to track the metrics that are most useful to you for monitoring performance, extracting insights, or enabling forecasts.
These two open source projects should be a perfect fit for your DevOps monitoring projects and should take no time at all for you to set up and customize.
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.














